
Thị giác máy tính (computer vision) đề cập đến toàn bộ quá trình mô phỏng tầm nhìn của con người trong một bộ máy phi sinh học. Điều này bao gồm việc chụp ảnh ban đầu, phát hiện và nhận dạng đối tượng, nhận biết bối cảnh tạm thời giữa các cảnh và phát triển sự hiểu biết ở mức độ cao về những gì đang xảy ra trong khoảng thời gian thích hợp.
Công nghệ này từ lâu đã trở nên phổ biến trong khoa học viễn tưởng, và vì thế, chúng thường được thừa nhận như một điều điều hiển nhiên. Trong thực tế, một hệ thống cung cấp khả năng thị giác máy tính đáng tin cậy, chính xác và trong thời gian thực là một vấn đề đầy thách thức vẫn chưa được phát triển một cách đầy đủ.
Khi các hệ thống này trưởng thành, sẽ có vô số ứng dụng dựa vào thị giác máy tính như một thành phần chính. Những ví dụ điển hình đó là xe hơi tự lái, robot tự động, máy bay không người lái, thiết bị hình ảnh y tế thông minh hỗ trợ phẫu thuật và cấy ghép phẫu thuật phục hồi thị lực của con người.

Một vấn đề phức tạp và khó khăn
Mặc dù thị giác máy tính hứa hẹn rất lớn trong tương lai, nhưng nó mang theo một sự phức tạp vốn có và luôn là thách thức đối với các hệ thống máy tính. Một phần của sự phức tạp là do thực tế thị giác máy tính không phải là một nhiệm vụ duy nhất. Thay vào đó, nó là một chuỗi các nhiệm vụ không đơn giản mà mỗi yêu cầu sử dụng các thuật toán phức tạp và đủ sức mạnh tính toán để hoạt động trong thời gian thực.
Ở cấp độ cao, các tác vụ phụ của thị giác máy tính là phát hiện và phân đoạn đối tượng, phân loại hình ảnh, theo dõi đối tượng, gắn nhãn hình ảnh với các mô tả có ý nghĩa (ví dụ như chú thích hình ảnh) và cuối cùng, hiểu ý nghĩa của toàn bộ bối cảnh.
Thị giác máy tính trong quá khứ
Các hệ thống thị giác máy tính truyền thống là sự kết hợp của các thuật toán phối hợp với nhau trong nỗ lực giải quyết các nhiệm vụ nói trên. Mục tiêu chính là trích xuất các đặc điểm (feature) từ hình ảnh, bao gồm các tác vụ phụ như phát hiện cạnh, phát hiện góc và phân đoạn dựa trên màu. Độ chính xác của các thuật toán được sử dụng để trích xuất các đặc điểm phụ thuộc vào thiết kế và tính linh hoạt của từng thuật toán.
Ví dụ về các thuật toán trích xuất feature truyền thống là Scale-invariant feature transform (SIFT), Speeded up robust features (SURF) và Binary Robust Independent Elementary Features (BRIEF). Các thuật toán khác nhau thực hiện với mức độ thành công khác nhau, tùy thuộc vào loại và chất lượng của hình ảnh được sử dụng làm đầu vào. Cuối cùng, độ chính xác của toàn bộ hệ thống phụ thuộc vào các phương pháp được sử dụng để trích xuất các features. Khi các features đã được trích xuất, việc phân tích được thực hiện bằng các phương pháp Machine Learning truyền thống.
Vấn đề chính với cách tiếp cận này là hệ thống cần được cho biết những đặc điểm cần tìm trong hình ảnh. Về cơ bản, do thuật toán hoạt động như đã được xác định bởi nhà thiết kế thuật toán, các features được trích xuất được thiết kế bởi con người. Trong các triển khai như vậy, hiệu suất kém của thuật toán có thể được xử lý thông qua tinh chỉnh, chẳng hạn như bằng cách điều chỉnh các tham số hoặc sửa đổi cấp mã để điều chỉnh hành vi. Tuy nhiên, những thay đổi như thế này cần phải được thực hiện thủ công và được mã hóa cứng hoặc cố định cho một ứng dụng cụ thể.
Đóng góp từ Deep Learning
Mặc dù vẫn còn những trở ngại đáng kể trong con đường phát triển của thị giác máy tính đến “cấp độ con người”, các hệ thống Deep Learning đã đạt được tiến bộ đáng kể trong việc xử lý một số nhiệm vụ phụ có liên quan. Lý do cho sự thành công này một phần dựa trên trách nhiệm bổ sung được giao cho các hệ thống deep learning.
Điều hợp lý để nói rằng sự khác biệt lớn nhất với các hệ thống deep learning là chúng không còn cần phải được lập trình để tìm kiếm các đặc điểm cụ thể. Thay vì tìm kiếm các đặc điểm cụ thể bằng thuật toán được lập trình cẩn thận, các mạng lưới thần kinh bên trong các hệ thống deep learning được đào tạo. Ví dụ: nếu ô tô trong hình ảnh bị phân loại sai thành xe máy thì bạn không tinh chỉnh các tham số hoặc viết lại thuật toán. Thay vào đó, bạn tiếp tục đào tạo cho đến khi hệ thống làm cho đúng.
Với sức mạnh tính toán tăng lên được cung cấp bởi các hệ thống deep learning hiện đại, có sự tiến bộ ổn định và đáng chú ý hướng tới điểm mà một máy tính sẽ có thể nhận ra và phản ứng với mọi thứ mà nó nhìn thấy.
Nhìn vào một số ứng dụng thực sự
Phân loại hình ảnh
Phân loại là quá trình dự đoán một lớp hoặc nhãn cụ thể cho một thứ được xác định bởi một tập hợp các điểm dữ liệu. Các hệ thống machine learning xây dựng các mô hình dự đoán có lợi ích to lớn nhưng thường không thấy được cho mọi người. Ví dụ: phân loại email spam đáng tin cậy có nghĩa là hộp thư đến trung bình ít gánh nặng hơn và dễ quản lý hơn. Mặc dù người dùng cuối trung bình dường như không nhận thức được sự phức tạp của vấn đề và số lượng lớn xử lý cần thiết để giảm thiểu vấn đề, nhưng lợi ích rất rõ ràng.
Phân loại hình ảnh là một tập hợp con của vấn đề phân loại, trong đó toàn bộ hình ảnh được gán nhãn. Có lẽ một bức ảnh sẽ được phân loại là một bức ảnh ban ngày hoặc ban đêm. Hoặc, theo cách tương tự, hình ảnh của ô tô và xe máy sẽ được tự động đặt vào các nhóm của riêng họ.
Có vô số danh mục, hoặc các lớp, trong đó một hình ảnh cụ thể có thể được phân loại. Xem xét một quy trình thủ công trong đó các hình ảnh được so sánh và các hình ảnh tương tự được nhóm theo các đặc điểm tương tự, nhưng không nhất thiết phải biết trước những gì bạn đang tìm kiếm. Rõ ràng, đây là một nhiệm vụ khó khăn. Để làm cho nó thậm chí nhiều hơn như vậy, giả sử rằng tập hợp các số hình ảnh trong hàng trăm ngàn. Rõ ràng là cần có một hệ thống tự động để thực hiện việc này nhanh chóng và hiệu quả.
Kiến trúc deep learning để phân loại hình ảnh thường bao gồm các lớp chập, làm cho nó trở thành một mạng nơ ron tích chập (CNN). Một số siêu đường kính, như số lượng các lớp chập và hàm kích hoạt cho mỗi lớp, sẽ phải được đặt. Đây là một phần không tầm thường của quá trình mà nó nằm ngoài phạm vi của cuộc thảo luận này. Tuy nhiên, là điểm khởi đầu, người ta thường có thể chọn các giá trị này dựa trên nghiên cứu hiện có.
Trên hệ thống như vậy là AlexNet, một CNN đã thu hút sự chú ý khi chiến thắng Thử thách nhận dạng hình ảnh quy mô lớn ImageNet (ILSVRC) năm 2012. Một mô hình được nghiên cứu kỹ lưỡng khác là Mạng thần kinh dư (ResNet), sau này đã chiến thắng thử thách tương tự, cũng như cuộc thi Đối tượng chung của Microsoft trong bối cảnh (MS COCO) vào năm 2015.
Phân loại hình ảnh cùng với việc bản địa hóa
Ứng dụng thứ hai của deep learning cho thị giác máy tính là Phân loại hình ảnh với bản địa hóa. Vấn đề này là một chuyên môn của phân loại hình ảnh, với yêu cầu bổ sung rằng đối tượng trong ảnh được đặt đầu tiên, và sau đó một hộp giới hạn được vẽ xung quanh nó.
Đây là một vấn đề khó khăn hơn so với phân loại hình ảnh và nó bắt đầu bằng việc xác định liệu chỉ có một đối tượng duy nhất được mô tả. Nếu vậy, hoặc nếu số lượng đối tượng được biết, thì mục tiêu là xác định vị trí của từng đối tượng và xác định bốn góc của hộp giới hạn tương ứng.
Quá trình này sẽ là một bước cần thiết trong một hệ thống chịu trách nhiệm nhận dạng xe. Hãy xem xét một hệ thống tự động duyệt hình ảnh của xe ô tô và được đảm bảo rằng có một chiếc xe duy nhất chứa trong cảnh. Khi chiếc xe đã được định vị, các thuộc tính như nhãn hiệu, kiểu dáng và màu sắc có thể được xác định.
Nhiệm vụ này có thể được thực hiện bằng cách sử dụng một mô hình deep learning phổ biến, chẳng hạn như AlexNet hoặc ResNet, và sửa đổi lớp được kết nối đầy đủ để tạo hộp giới hạn. Như đã đề cập trước đây, có thể có một số tinh chỉnh để thực hiện về mặt cài đặt siêu đường kính hoặc sửa đổi kiến trúc cho hiệu quả trong một miền cụ thể, nhưng trong thực tế, các kiến trúc cơ bản hoạt động tốt. Sẽ cần phải có đủ dữ liệu huấn luyện bao gồm các ví dụ với cả mô tả đối tượng và hộp giới hạn được xác định rõ ràng, mặc dù các bộ dữ liệu mẫu có sẵn cho mục đích này.
Khó khăn với nhiệm vụ này xảy ra khi có một số lượng đối tượng không xác định trong hình. Trong phần lớn các hình ảnh, đặc biệt là những hình ảnh được chụp ở khu vực công cộng, sẽ có nhiều khả năng như người, phương tiện, cây cối và động vật khác nhau. Đối với loại môi trường này, vấn đề trở thành một trong những phát hiện đối tượng.
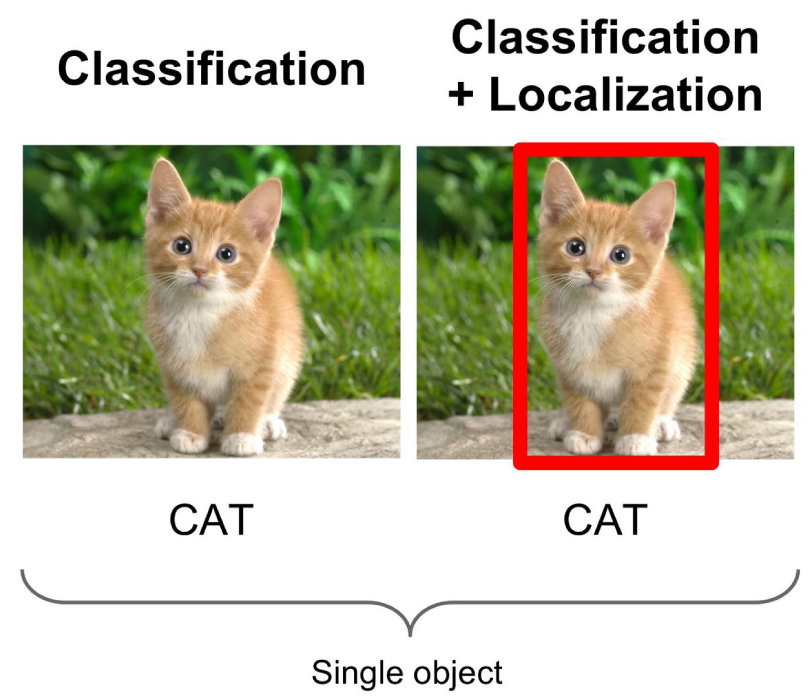
Nguồn: CS231n (Bài giảng Stanford)
Phát hiện đối tượng
Phát hiện đối tượng là phân loại hình ảnh với nội địa hóa, nhưng trong các hình ảnh có thể chứa nhiều đối tượng. Đây là một lĩnh vực nghiên cứu tích cực và quan trọng bởi vì các hệ thống thị giác máy tính sẽ được sử dụng trong robot và xe tự lái sẽ phải chịu những hình ảnh rất phức tạp. Xác định vị trí và xác định mọi đối tượng chắc chắn sẽ là một phần quan trọng trong quyền tự chủ của họ.
Kiến trúc cần thiết để phát hiện đối tượng khác nhau theo một cách quan trọng. Cụ thể, kích thước của vectơ đầu ra không cố định. Ví dụ, nếu có một đối tượng trong hình, thì sẽ có bốn tọa độ xác định hộp giới hạn. Giá trị tĩnh và được xác định trước này hoạt động bằng cách sử dụng các kiến trúc đã đề cập trước đó. Tuy nhiên, khi số lượng đối tượng tăng lên, số lượng tọa độ cũng tăng theo. Đặc biệt là số lượng đối tượng không được biết trước, điều này đòi hỏi phải điều chỉnh trong trang điểm của mạng lưới thần kinh.
Một kiến trúc được sửa đổi như vậy là R-CNN: Khu vực có các tính năng CNN. Cách tiếp cận này liên quan đến việc tạo các vùng quan tâm được thu nhỏ theo kích thước cố định và sau đó chuyển tiếp các vùng này thành một mô hình như AlexNet. Trong khi hệ thống này tạo ra kết quả tốt, nó đắt tiền về mặt tính toán và quá chậm đối với hệ thống thị giác máy tính thời gian thực.
Với mục tiêu tăng tốc R-CNN, đã có nhiều điều chỉnh khác nhau đối với kiến trúc. Đầu tiên là Fast R-CNN, chứa tối ưu hóa và các cải tiến khác giúp cải thiện cả tốc độ và độ chính xác phát hiện. Tiến lên một bước nữa, thế hệ tiếp theo, mô hình R-CNN nhanh hơn, bao gồm một CNN bổ sung có tên Mạng đề xuất khu vực (RPN).
RPN được đào tạo để tạo các vùng chất lượng cao được gửi tới mô hình R-CNN nhanh. Sự kết hợp của các thuật toán này dẫn đến sự gia tăng tốc độ ấn tượng và thực sự trên con đường hướng tới phát hiện đối tượng thời gian thực trong các hệ thống thị giác máy tính.

(Nguồn: https://machinelearningmastery.com/appluggest-of-deep-learning-for-computer-vision/)
Tái thiết hình ảnh
Tái tạo hình ảnh là nhiệm vụ tái tạo các phần bị thiếu hoặc hỏng của hình ảnh. Đây là một công việc khó khăn có thể được nghĩ đến về một chuyển đổi hoặc bộ lọc, có thể không có đánh giá khách quan. Mặc dù thực sự có thể đảm bảo rằng các thuộc tính có thể nhìn thấy của hình ảnh có thể được kết hợp chặt chẽ, rõ ràng là không hợp lý khi yêu cầu máy tính tạo lại chi tiết mà không có tham chiếu. Như vậy, các hệ thống tái tạo hình ảnh có các giới hạn phụ thuộc rất nhiều vào mức độ hình ảnh gốc có sẵn để học hỏi.
Một mô hình thực hiện tái tạo hình ảnh được đặt tên là Mạng thần kinh tái tạo Pixel. Đây là một hệ thống sử dụng Mạng thần kinh tái phát (RNN) để dự đoán các pixel bị thiếu trong một hình ảnh dọc theo hai chiều không gian.
Ví dụ về các ứng dụng để tái tạo hình ảnh là phục hồi ảnh hoặc phim đen trắng. Trong một chiếc xe tự lái, tái tạo hình ảnh có thể được sử dụng để nhìn xa hơn các vật cản nhỏ, chẳng hạn như một biển chỉ dẫn giữa xe và người đi bộ đang được theo dõi.

(Tái tạo và tô màu hình ảnh. Nguồn: NVIDIA và blog.floydhub.com)
Theo dõi đối tượng
Đến thời điểm này, các tác vụ đã được tập trung vào các hoạt động có thể hoạt động với một hình ảnh tĩnh duy nhất. Tuy nhiên, một mục tiêu quan trọng trong thị giác máy tính là có khả năng nhận ra một sự kiện đang xảy ra trong một khoảng thời gian. Với một hình ảnh duy nhất để mô tả trực quan các sự kiện cùng một lúc, nó đòi hỏi một loạt các hình ảnh để có được sự hiểu biết lớn hơn về tổng thể.
Theo dõi đối tượng là một ví dụ như vậy, trong đó mục tiêu là theo dõi một đối tượng cụ thể trong chuỗi hình ảnh hoặc video. Ảnh chụp bắt đầu chuỗi chứa đối tượng có hộp giới hạn và thuật toán theo dõi xuất ra hộp giới hạn cho tất cả các khung tiếp theo. Lý tưởng nhất, hộp giới hạn sẽ đóng gói hoàn hảo cùng một đối tượng miễn là nó có thể nhìn thấy. Hơn nữa, nếu đối tượng nên bị che khuất và sau đó xuất hiện lại, việc theo dõi nên được duy trì. Với mục đích của cuộc thảo luận này, chúng ta có thể giả sử rằng đầu vào của thuật toán theo dõi đối tượng là đầu ra từ thuật toán phát hiện đối tượng.
Theo dõi đối tượng là quan trọng đối với hầu hết mọi hệ thống thị giác máy tính có chứa nhiều hình ảnh. Trong xe hơi tự lái, ví dụ, người đi bộ và các phương tiện khác thường phải tránh ở mức ưu tiên rất cao. Theo dõi các đối tượng khi chúng di chuyển sẽ không chỉ giúp tránh va chạm thông qua việc sử dụng các thao tác chia giây, mà còn, mô hình có thể cung cấp thông tin liên quan cho các hệ thống khác sẽ cố gắng dự đoán hành động tiếp theo của chúng.
Thư viện thị giác máy tính Nguồn mở, OpenCV, chứa API theo dõi đối tượng. Có một số thuật toán có sẵn, mỗi thuật toán thực hiện khác nhau tùy thuộc vào đặc điểm của video, cũng như chính đối tượng. Ví dụ, một số thuật toán hoạt động tốt hơn khi đối tượng được theo dõi trở nên bị tắc nghẽn trong giây lát. OpenCV chứa cả thuật toán cổ điển và hiện đại để xử lý nhiều tác vụ trong thị giác máy tính và là một tài nguyên hữu ích để phát triển các hệ thống như vậy.

(Nguồn: neurohive.io )
Phần kết luận
Thị giác máy tính là một lĩnh vực thú vị và quan trọng, được ứng dụng trên nhiều lĩnh vực. Việc sử dụng hiệu quả chúng không chỉ đơn thuần là có liên quan đến, mà nó còn mang tính chất bắt buộc và cực kỳ quan trọng đối với các ứng dụng nâng cao như robot tự động và các loại phương tiện tự vận hành.
Hệ thống thị giác máy tính truyền thống không chỉ chậm chạp mà còn thiếu tính linh hoạt. Chúng yêu cầu rất nhiều đầu vào từ nhà phát triển và không dễ dàng điều chỉnh theo môi trường mới. Mặt khác, các hệ thống deep learning, xử lý các nhiệm vụ thị giác máy tính từ đầu đến cuối và không yêu cầu thông tin bên ngoài hoặc đào tạo liên tục ở cùng mức độ.
Những tiến bộ trong hệ thống deep learning và sức mạnh tính toán đã giúp cải thiện tốc độ, độ chính xác và độ tin cậy tổng thể của hệ thống thị giác máy tính. Khi các mô hình deep learning cải thiện và sức mạnh tính toán trở nên dễ dàng hơn, chúng ta sẽ tiếp tục đạt được những tiến bộ và sự ổn định đối với các hệ thống tự vận hành có thể thực sự nắm bắt và phản ứng với những gì chúng cảm nhận.
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI