
Tạo ra một hệ thống máy học tuyệt vời là một nghệ thuật.
Có rất nhiều vấn đề cần xem xét khi xây dựng một hệ thống machine learning tốt. Nhưng thường thì chúng ta, những nhà khoa học dữ liệu, chỉ quan tâm đến một số phần của dự án.
Hầu hết thời gian là dành cho việc tao ra mô hình (model), nhưng trong thực tế, thành công hay thất bại của dự án Machine Learning phụ thuộc vào rất nhiều yếu tố khác.

Một machine learning pipeline không chỉ đơn thuần để tạo ra mô hình
Điều cần thiết là phải hiểu những gì xảy ra trước và sau khi đào tạo mô hình, sau đó triển khai nó trong môi trường production (môi trường vận hành thực tế).
Bài đăng này sẽ giải thích những gì liên quan đến một “pipeline” từ đầu đến cuối cho dự án data science.
1. Định nghĩa vấn đề

Điều này là rõ ràng – Xác định một vấn đề.
Và, đây có thể là phần quan trọng nhất của toàn bộ bài toán.
Vậy, làm thế nào để xác định một vấn đề cho Machine learning?
Vâng, điều đó phụ thuộc vào rất nhiều yếu tố. Trong số tất cả các yếu tố mà chúng tôi xem xét, điều đầu tiên là phải hiểu nó sẽ mang lại lợi ích như thế nào cho doanh nghiệp .
Đó là chén thánh của bất kỳ dự án khoa học dữ liệu nào. Nếu dự án của bạn không giúp ích cho việc kinh doanh, nó sẽ không được triển khai.
Khi bạn có một ý tưởng và bạn xác định khả năng tương thích với doanh nghiệp, bạn cần xác định một số liệu thành công.
Bây giờ, thành công trông như thế nào?
Là nó chính xác 90% hay chính xác 95% hay chính xác 99%.
Chà, tôi có thể hài lòng với độ chính xác dự đoán 70% vì một người bình thường sẽ không vượt qua độ chính xác đó bao giờ và trong khi đó, bạn có thể tự động hóa quy trình.
Coi chừng, đây không phải là lúc để đặt mục tiêu cao cả; đã đến lúc phải logic hóa và cảm nhận về việc mỗi % của độ chính xác thay đổi có thể ảnh hưởng đến thành công như thế nào.
Ví dụ: Đối với vấn đề dự đoán lần nhấp chuột / Ứng dụng gian lận, mức tăng chính xác 1% sẽ thúc đẩy lợi nhuận kinh doanh so với mức tăng chính xác 1% trong dự đoán tình cảm đánh giá.
Không phải tất cả việc gia tăng độ chính xác đều được tạo ra như nhau
2. Dữ liệu

Có một số câu hỏi bạn sẽ cần trả lời tại thời điểm thu thập dữ liệu và tạo dữ liệu cho mô hình học máy của bạn.
Câu hỏi quan trọng nhất để trả lời ở đây là: Mô hình của bạn có cần phải làm việc trong thời gian thực không?
Nếu đó là trường hợp, bạn không thể sử dụng một hệ thống như Hive / Hadoop để lưu trữ dữ liệu vì các hệ thống đó có thể gây ra nhiều độ trễ và phù hợp để xử lý ngoại tuyến theo lô (batch).
Mô hình của bạn có cần được đào tạo trong thời gian thực không?
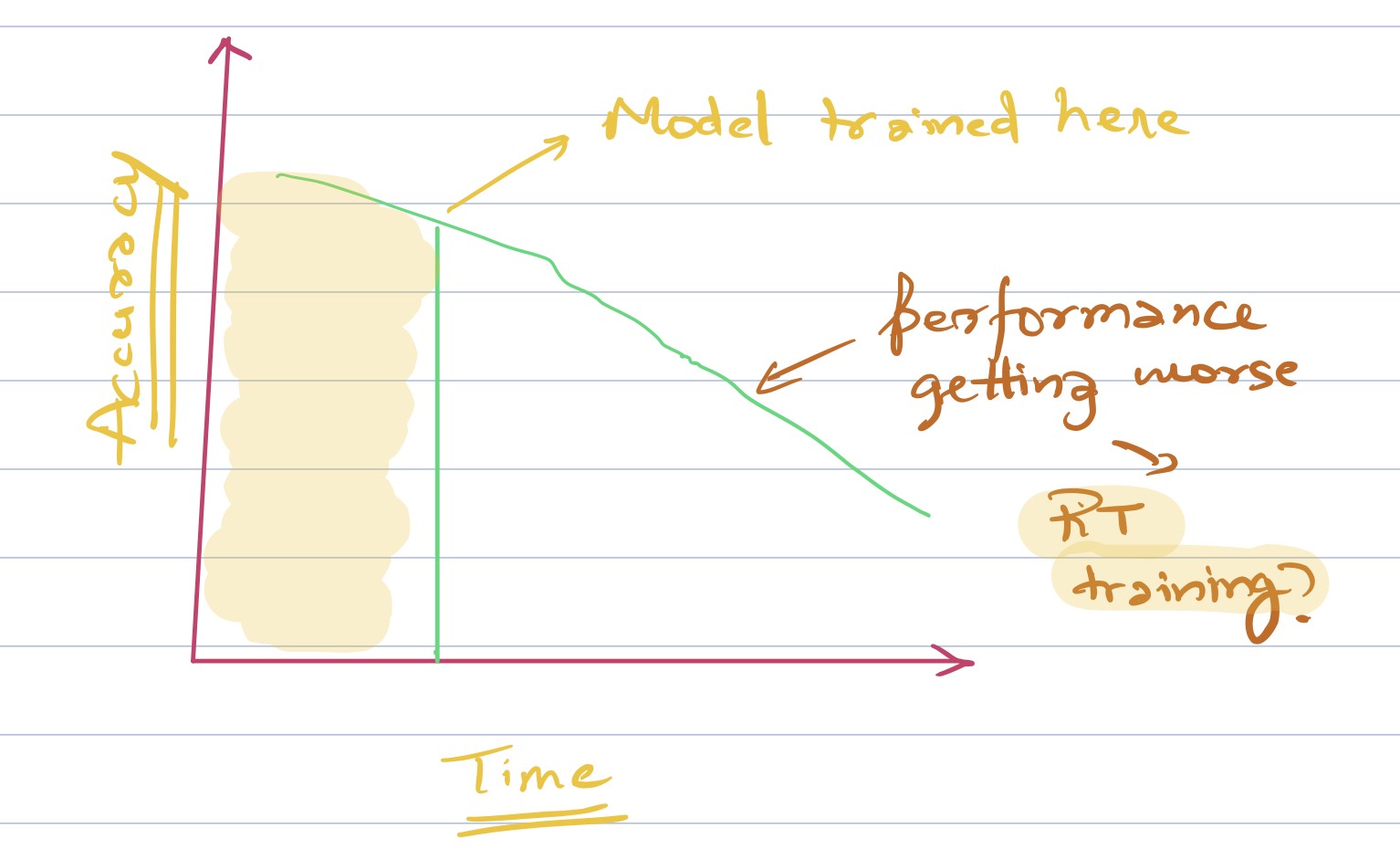
Nếu hiệu suất của mô hình machine learning (ML) của bạn giảm theo thời gian như trong hình trên, bạn có thể muốn cân nhắc đào tạo theo thời gian thực (realtime). Đào tạo realtime có thể có lợi cho hầu hết các hệ thống dự đoán nhấp chuột vì xu hướng internet thay đổi khá nhanh.
Có sự không nhất quán giữa dữ liệu kiểm tra và đào tạo không?
Hay nói một cách đơn giản – bạn có nghi ngờ rằng dữ liệu sản xuất đến từ một bảng phân phối khác với dữ liệu đào tạo không?
Ví dụ: Trong một hệ thống đào tạo thời gian thực cho vấn đề dự đoán nhấp chuột, bạn hiển thị cho người dùng các quảng cáo và anh ta không nhấp vào. Đó có phải là một ví dụ thất bại? Có thể người dùng nhấp thường sau 10 phút. Nhưng bạn đã tạo dữ liệu và đào tạo mô hình của bạn về điều đó.
Có rất nhiều yếu tố bạn nên xem xét trong khi chuẩn bị dữ liệu cho các mô hình của mình. Bạn cần đặt câu hỏi và suy nghĩ về quá trình kết thúc để kết thúc để thành công ở giai đoạn này.
Khi xử lý dữ liệu thời gian thực là vấn đề sống còn, một giải pháp về phần cứng hợp lý là điều tiên quyết.
Hãy tham khảo các giải pháp lưu trữ dữ liệu hiệu năng cao từ Thế Giới Máy Chủ để sẵn sàng cho hệ thống Deep Learning của bạn.
3. Đánh giá

Làm thế nào để chúng ta đánh giá hiệu suất của mô hình đào tạo?
Tiêu chuẩn vàng ở đây là sự phân chia train-test-validation.
Thường xuyên thực hiện một bộ train-test-validation, bằng cách lấy mẫu, chúng ta quên mất một giả định ngầm – Dữ liệu hiếm khi được IID (phân phối độc lập và giống hệt nhau).
Nói một cách đơn giản, giả định của chúng tôi rằng mỗi điểm dữ liệu độc lập với nhau và xuất phát từ cùng một bản phân phối là lỗi to nhất nếu hoàn toàn không chính xác.
Đối với một công ty internet, điểm dữ liệu từ năm 2007 rất khác với điểm dữ liệu xuất hiện vào năm 2019. Họ không đến từ cùng một bản phân phối vì rất nhiều yếu tố – tốc độ internet là quan trọng nhất.
Nếu bạn gặp vấn đề với phép dự đoán mèo và chó, bạn khá giỏi với việc lấy mẫu ngẫu nhiên. Nhưng, trong hầu hết các mô hình học máy, nhiệm vụ là dự đoán cho tương lai.
Bạn có thể suy nghĩ về việc chia dữ liệu của mình bằng cách sử dụng biến thời gian thay vì lấy mẫu ngẫu nhiên từ dữ liệu. Ví dụ: đối với vấn đề dự đoán nhấp chuột, bạn có thể có tất cả dữ liệu trong quá khứ của mình cho đến tháng trước dưới dạng dữ liệu huấn luyện và dữ liệu cho tháng trước dưới dạng xác thực.
Điều tiếp theo bạn sẽ cần nghĩ đến là mô hình cơ sở.
Giả sử chúng tôi sử dụng RMSE làm chỉ số đánh giá cho các mô hình chuỗi thời gian của chúng tôi. Chúng tôi đã đánh giá mô hình trên bộ thử nghiệm và RMSE ra đời là 4,8.
Đó có phải là một RMSE tốt? Làm sao mà chúng ta biết được? Chúng ta cần một RMSE cơ bản. Điều này có thể đến từ một mô hình hiện đang làm việc cho cùng một nhiệm vụ. Hoặc bằng cách sử dụng một số mô hình đơn giản. Đối với mô hình chuỗi thời gian, một đường cơ sở để đánh bại là dự đoán ngày cuối cùng. tức là dự đoán số vào ngày hôm trước.
Đối với các mô hình phân loại NLP, tôi thường đặt đường cơ sở là số liệu đánh giá (Độ chính xác, F1, mất log) của các mô hình hồi quy Logistic trên Countvectorizer (Bag of words).
Bạn cũng nên suy nghĩ về cách bạn sẽ phá vỡ đánh giá trong nhiều nhóm để mô hình của bạn không gây ra những thành kiến không cần thiết.

Năm ngoái, Amazon có tin tức về một công cụ tuyển dụng AI bí mật cho thấy sự thiên vị đối với phụ nữ. Để lưu mô hình Machine Learning của chúng tôi khỏi những mâu thuẫn như vậy, chúng tôi cần đánh giá mô hình của chúng tôi trên các nhóm khác nhau. Có thể mô hình của chúng tôi không chính xác cho phụ nữ vì nó dành cho nam giới vì số lượng phụ nữ trong dữ liệu đào tạo ít hơn rất nhiều.
Hoặc có thể một mô hình dự đoán nếu một sản phẩm sẽ được mua hoặc không được đưa ra một chế độ xem hoạt động khá tốt cho một danh mục sản phẩm cụ thể chứ không phải cho các danh mục sản phẩm khác.
Giữ những điều như vậy trong tâm trí trước và suy nghĩ chính xác về những gì có thể sai với một phương pháp đánh giá cụ thể là điều chắc chắn có thể giúp chúng ta thiết kế một hệ thống ML tốt.
4. Tính năng

Các tính năng tốt là xương sống của bất kỳ mô hình học máy nào. Và thường là phần mà bạn sẽ dành nhiều thời gian nhất. Tôi đã thấy rằng đây là phần mà bạn có thể điều chỉnh để đạt hiệu suất mô hình tối đa.
Tạo tính năng tốt thường cần kiến thức tên miền, sáng tạo và nhiều thời gian.
Trên hết, bài tập tạo tính năng có thể thay đổi cho các mô hình khác nhau. Ví dụ: việc tạo tính năng rất khác nhau đối với các mạng thần kinh so với XGboost.
Hiểu các phương pháp khác nhau để tạo tính năng là một chủ đề khá lớn trong chính nó. Tôi đã viết một bài ở đây về sáng tạo tính năng. Hãy xem:
Khi bạn tạo nhiều tính năng, điều tiếp theo bạn có thể muốn làm là xóa các tính năng dư thừa. Dưới đây là một số phương pháp để làm điều đó
5. Làm mẫu
 Sách ML giải thích
Sách ML giải thích
Bây giờ đến phần chúng ta chủ yếu quan tâm. Và tại sao không? Đó là mảnh mà chúng tôi cuối cùng cung cấp vào cuối dự án. Và đây là phần mà chúng tôi đã dành tất cả những giờ đó để thu thập và làm sạch dữ liệu, tạo tính năng và không có gì.
Vậy chúng ta cần nghĩ gì trong khi tạo ra một mô hình?
Câu hỏi đầu tiên mà bạn có thể cần phải tự hỏi mình là nếu mô hình của bạn cần được giải thích?
Có khá nhiều trường hợp sử dụng mà doanh nghiệp có thể muốn một mô hình có thể hiểu được. Một trường hợp sử dụng như vậy là khi chúng ta muốn thực hiện mô hình phân bổ. Ở đây chúng tôi xác định ảnh hưởng của các luồng quảng cáo khác nhau (TV, đài phát thanh, báo, v.v.) đến doanh thu. Trong những trường hợp như vậy, hiểu được phản hồi từ mỗi luồng quảng cáo trở nên cần thiết.
Nếu chúng tôi cần tối đa hóa độ chính xác hoặc bất kỳ số liệu nào khác, chúng tôi vẫn sẽ muốn sử dụng các mô hình hộp đen như NeuralNets hoặc XGBoost.
Ngoài lựa chọn mô hình, bạn cũng nên có những thứ khác:
- Kiến trúc mô hình: Có bao nhiêu lớp cho NN hoặc bao nhiêu cây cho GBT hoặc cách bạn cần để tạo tương tác tính năng cho mô hình tuyến tính.
- Làm thế nào để điều chỉnh siêu âm?: Bạn nên cố gắng tự động hóa phần này. Có rất nhiều công cụ trên thị trường cho việc này. Tôi có xu hướng sử dụng hyperopt.
6. Thử nghiệm

Bây giờ bạn đã tạo mô hình của bạn.
Nó hoạt động tốt hơn so với đường cơ sở / mô hình hiện tại của bạn. Làm thế nào chúng ta nên đi về phía trước?
Chúng tôi có hai lựa chọn-
- Đi vào một vòng lặp vô tận trong việc cải thiện mô hình của chúng tôi hơn nữa.
- Kiểm tra mô hình của chúng tôi trong cài đặt sản xuất, hiểu thêm về những gì có thể sai và sau đó tiếp tục cải thiện mô hình của chúng tôi với tích hợp liên tục.
Tôi là một fan hâm mộ của cách tiếp cận thứ hai. Trong khóa học thứ ba tuyệt vời của mình có tên là Dự án học máy cấu trúc trong Chuyên ngành học sâu Coursera , Andrew Ng nói –
Không nên bắt đầu thử thiết kế và xây dựng hệ thống hoàn hảo. Thay vào đó, hãy xây dựng và huấn luyện một hệ thống cơ bản một cách nhanh chóng – có lẽ chỉ trong vài ngày. Ngay cả khi hệ thống cơ bản khác xa với hệ thống tốt nhất mà bạn có thể xây dựng, bạn vẫn có thể kiểm tra cách thức hoạt động của hệ thống cơ bản: bạn sẽ nhanh chóng tìm ra manh mối chỉ cho bạn những hướng đi hứa hẹn nhất để đầu tư thời gian của bạn.
Một điều tôi cũng muốn nhấn mạnh là tích hợp liên tục . Nếu mô hình hiện tại của bạn hoạt động tốt hơn mô hình hiện tại, tại sao không triển khai nó trong sản xuất thay vì chạy sau khi tăng lợi nhuận?
Để kiểm tra tính hợp lệ của giả định rằng mô hình của bạn tốt hơn mô hình hiện có, bạn có thể thiết lập thử nghiệm A / B. Một số người dùng (Nhóm thử nghiệm) xem mô hình của bạn trong khi một số người dùng (Kiểm soát) xem dự đoán từ mô hình trước đó.
Bạn nên luôn luôn nhắm đến việc giảm thiểu thời gian để thử nghiệm trực tuyến đầu tiên cho mô hình của bạn. Điều này không chỉ tạo ra giá trị mà còn cho phép bạn hiểu những thiếu sót của mô hình của bạn với phản hồi thời gian thực mà sau đó bạn có thể làm việc.
Kết luận
Không có gì là đơn giản trong học máy. Và không có gì nên được giả định.
Bạn phải luôn luôn khó tính với bất kỳ quyết định nào bạn đã đưa ra trong khi xây dựng một Machine Learning Pipeline.
Một quyết định tìm kiếm đơn giản có thể là sự khác biệt giữa thành công hay thất bại của dự án machine learning của bạn.
Vì vậy, hãy suy nghĩ sáng suốt và suy nghĩ thật nhiều.
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI