
 Nguồn: https://striveiccv2021.github.io/STRIVE-ICCV2021/
Nguồn: https://striveiccv2021.github.io/STRIVE-ICCV2021/
Một Nhóm các nhà nghiên cứu từ Phòng thí nghiệm NEC, Trung tâm Nghiên cứu Palo Alto, Amazon, PARC và Đại học Stanford đang làm việc cùng nhau để giải quyết vấn đề thay thế văn bản trong cảnh hiện trường thực tế trong các video (Scene Deep Video Text Replacement). Ứng dụng chính của họ đằng sau nghiên cứu này là nhằm tạo các nội dung được cá nhân hóa cho các mục đích tiếp thị và quảng cáo. Ví dụ: thay thế một từ trên bảng hiệu cửa hàng bằng tên hoặc thông điệp được cá nhân hóa, như trong hình bên dưới.
 https://arxiv.org/pdf/2109.02762.pdf
https://arxiv.org/pdf/2109.02762.pdf

Về mặt kỹ thuật, một số nỗ lực đã được thực hiện để tự động hóa việc thay thế văn bản trong ảnh tĩnh dựa trên các nguyên tắc chuyển kiểu sâu (deep style transfer). Nhóm nghiên cứu đang đưa tiến trình này và nghiên cứu của họ vào việc giải quyết vấn đề thay thế văn bản trong video. Thay thế văn bản video không phải là một công việc dễ dàng. Nó phải đáp ứng những thách thức phải đối mặt đối với ảnh tĩnh đồng thời tính đến thời gian và các hiệu ứng như thay đổi ánh sáng, mờ do chuyển động của máy ảnh hoặc chuyển động của đối tượng.
Một cách tiếp cận để giải quyết việc thay thế video-test có thể là đào tạo module chuyển kiểu văn bản (text style transfer) dựa trên hình ảnh trên các frame riêng lẻ đồng thời kết hợp các ràng buộc nhất quán tạm thời trong việc mất liên kết với network. Nhưng với cách tiếp cận này, network thực hiện chuyển kiểu văn bản sẽ thêm gánh nặng với việc xử lý các hiệu ứng hình học và chuyển động tạo ra trong video.
Do đó, nhóm nghiên cứu đã có một cách tiếp cận rất khác . Đầu tiên, họ trích xuất các vùng văn bản cần quan tâm – Regions Of Interest (ROI) và đào tạo mạng gọi là Spatio-temporal transformer network (STTN) để Chuẩn hóa ROI sao cho chúng nhất quán theo thời gian. Tiếp theo, họ quét video và chọn frame tham chiếu có chất lượng văn bản cao được đo về độ sắc nét, kích thước và hình học của văn bản.
Nhóm nghiên cứu đã thực hiện thay thế văn bản bằng hình ảnh tĩnh trên khung hình nhất định bằng SRNet, một phương pháp hiện đại được đào tạo về khung hình video. Tiếp theo, văn bản mới được chuyển sang các frame khác bằng một module mới được gọi là TPM (text propagation module) để xem xét các thay đổi về hiệu ứng ánh sáng và hiệu ứng mờ. Như đầu vào, TPM lấy tham chiếu và khung hiện tại từ video gốc. Nó kết thúc với một sự chuyển đổi hình ảnh giữa cặp với ứng dụng hướng tới hệ quy chiếu đã thay đổi do SRNet tạo ra. Phần quan trọng là TPM tính đến tính nhất quán theo thời gian của một hình ảnh khi học các phép biến đổi theo cặp.
Các nhà nghiên cứu đã đặt tên cho khung của họ liên quan đến cách tiếp cận nghiên cứu trên là STRIVE (Scene Text Replacement In VidEos), và nó được hiển thị trong hình bên dưới.
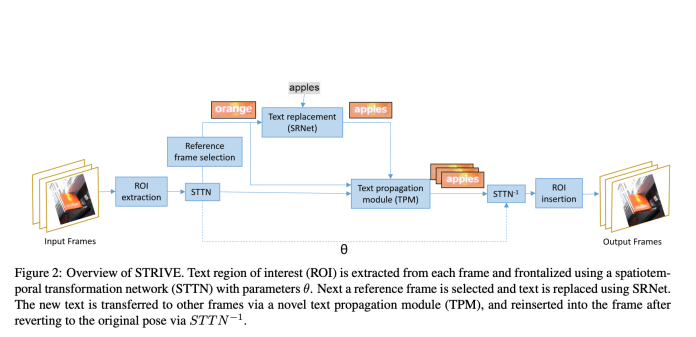 Nguồn: https://arxiv.org/pdf/2109.02762.pdf
Nguồn: https://arxiv.org/pdf/2109.02762.pdf
Sử dụng cách tiếp cận được đề xuất, các nhà nghiên cứu có thể hiển thị kết quả trên các video thực đa dạng và đầy thử thách với khả năng chuyển tải văn bản thực tế, hiệu suất tốt, chất lượng cao và tốc độ suy luận vượt trội so với các lựa chọn thay thế. Họ cũng giới thiệu dataset tổng hợp và thế giới thực mới với các đối tượng văn bản được ghép nối. Theo nhóm nghiên cứu, đây có thể là nỗ lực đầu tiên trong việc thay thế văn bản bằng video sâu.
Tài liệu: https://arxiv.org/pdf/2109.02762.pdf
Github: https://striveiccv2021.github.io/STRIVE-ICCV2021/
Dataset: https://github.com/striveiccv2021/STRIVE-ICCV2021/
Video minh họa Scene Text Replacement:
https://youtu.be/cJbESd1PVGc
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI