
Khi nói đến điện toán hiệu năng cao hay High Performance Computing (HPC), chúng ta thường hướng đến việc giải quyết một số loại bài toán. Những bài toán này thường sẽ rơi vào một trong bốn loại:
Nặng về Xử lý (compute intensive) – Một bài toán duy nhất đòi hỏi một lượng lớn tính toán.
Nặng về Bộ nhớ (memory intensive) – Một bài toán duy nhất đòi hỏi một lượng lớn bộ nhớ.
Nặng về Dữ liệu (data intensive) – Một bài toán duy nhất hoạt động trên một tập dữ liệu lớn.
Thông lượng cao (throughput intensive) – Nhiều bài toán không liên quan được tính toán đồng loạt.
Bài viết này sẽ giới thiệu chi tiết về HPC giúp bạn hiểu rõ ý nghĩa của chúng trong việc giải quyết các bài toán phổ biến được liệt kê ở trên.

Các workload nặng về xử lý
Đầu tiên, chúng ta cùng xem xét các bài toán đòi hỏi nhiều về xử lý. Mục tiêu là phân phối công việc cho một bài toán duy nhất cho nhiều CPU để giảm thời gian xử lý càng nhiều càng tốt. Để thực hiện điều này, chúng ta cần thực hiện song song các bước của bài toán. Mỗi process hoặc thread, xử lý một phần của khối lượng công việc và thực hiện chúng một cách đồng thời. Các CPU thường cần trao đổi dữ liệu nhanh chóng, đòi hỏi phần cứng chuyên dùng cho việc giao tiếp. Ví dụ về các loại bài toán này có thể tìm thấy khi phân tích dữ liệu liên quan đến các tác vụ như mô hình hóa trong lĩnh vực tài chính, quản trị rủi ro hay chăm sóc sức khỏe. Đây có lẽ là phần lớn nhất trong các tập vấn đề của HPC và là lĩnh vực truyền thống của HPC.
Khi cố gắng giải quyết các vấn đề nặng về xử lý, chúng ta có thể nghĩ rằng việc thêm nhiều CPU sẽ giảm thời gian thực hiện. Điều này không phải lúc nào cũng đúng. Hầu hết các parallel codebase thường có cái mà chúng ta gọi là scaling-limit. Lý do là vì hệ thống bị quá tải bởi việc quản lý quá nhiều bản sao, ngoài ra còn do các ràng buộc cơ bản khác.
Điều này được tóm tắt trong luật định Amdahl.
Trong kiến trúc máy tính, định luật Amdahl là một công thức giúp tăng tốc độ lý thuyết về độ trễ của việc thực hiện một nhiệm vụ với khối lượng công việc cố định có thể được dự kiến của một hệ thống có tài nguyên được cải thiện. Nó được đặt theo tên của nhà khoa học máy tính Gene Amdahl, và được trình bày tại sự kiện AFIPS Spring Joint Computer Conference năm 1967.
Định luật Amdahl, thường được sử dụng trong điện toán song song để dự đoán sự tăng tốc lý thuyết khi sử dụng nhiều bộ xử lý. Ví dụ: nếu một chương trình cần 20 giờ sử dụng lõi xử lý đơn và một phần cụ thể của chương trình mất một giờ để thực thi thì không thể song song, trong khi 19 giờ (p = 0,95) thời gian thực hiện có thể được song song bất kể có bao nhiêu bộ xử lý được dành cho việc thực thi song song chương trình này, thời gian thực hiện tối thiểu không thể ít hơn một giờ quan trọng đó. Do đó, việc tăng tốc lý thuyết bị giới hạn tối đa 20 lần (1 / (1 – p) = 20). Vì lý do này, xử lý song song với nhiều bộ xử lý chỉ hữu ích cho các chương trình có bản chất song song tự nhiên – Wikipedia
Định luật Amdahl có thể được xây dựng theo cách sau, trong đó:
- S[latency] là sự tăng tốc lý thuyết của việc thực hiện toàn bộ nhiệm vụ;
- s là sự tăng tốc của một phần của nhiệm vụ được hưởng lợi từ tài nguyên hệ thống được cải thiện;
- p là tỷ lệ thời gian thực hiện mà phần được hưởng lợi từ các tài nguyên được cải thiện ban đầu bị chiếm dụng.
Hơn nữa,
Biểu đồ ví dụ: Nếu 95% chương trình có thể được song song, tốc độ tối đa theo lý thuyết sử dụng xử lý song song sẽ là 20 lần.
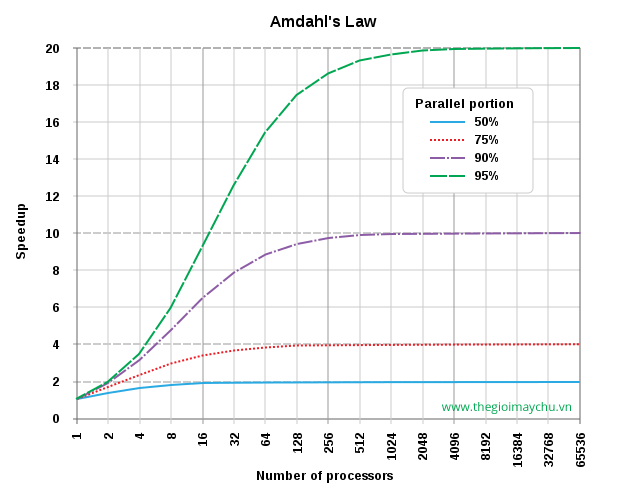
Điểm mấu chốt: Khi bạn tạo ra nhiều phần của bài toán có thể chạy đồng thời, bạn có thể phân chia công việc giữa nhiều bộ xử lý hơn và do đó, đạt được nhiều lợi ích hơn. Tuy nhiên, do sự phức tạp và chi phí vận hành, cuối cùng việc sử dụng nhiều CPU trở nên bất lợi thay vì thực sự hữu ích.
Có nhiều thư viện giúp hỗ trợ song song hóa bài toán, như OpenMP hoặc Open MPI, nhưng trước khi chuyển sang các thư viện này, chúng ta nên cố gắng tối ưu hóa hiệu suất trên một CPU, sau đó làm cho p càng lớn càng tốt.
Các workload nặng về bộ nhớ
Các workload nặng về bộ nhớ sẽ cần nhiều đến không gian bộ nhớ lớn, hơn là có nhiều CPU. Theo tôi, đây là một trong những các vấn đề khó giải quyết nhất và thường đòi hỏi sự cẩn thận cao khi thiết lập nên hệ thống của bạn. Lập trình và chuyển mã sẽ dễ dàng hơn vì bộ nhớ sẽ liền lạc, cho phép tạo ra một hình ảnh hệ thống duy nhất. Tuy nhiên, việc tối ưu hóa trở nên khó khăn hơn khi càng kéo dài xa ngày khởi tạo ban đầu của hệ thống vì tính đồng nhất của các component. Theo truyền thống, trong các data center, bạn sẽ không thay thế các máy chủ sau mỗi ba năm một lần. Nếu chúng ta muốn có nhiều tài nguyên hơn trong cluster, và chúng ta muốn hiệu năng được đồng nhất, bộ nhớ không đồng nhất sẽ tạo ra độ trễ thực tế. Chúng ta cũng phải suy nghĩ về sự kết nối giữa CPU và bộ nhớ.
Ngày nay, phần lớn trong số những lo ngại này đã được loại bỏ bởi các máy chủ thông dụng. Chúng ta có thể yêu cầu hàng nghìn instance giống nhau có cùng thông số kỹ thuật và phần cứng, và các công ty như Amazon Web Services rất vui lòng cho chúng ta sử dụng chúng.
Các workload nặng về dữ liệu
Đây có lẽ là loại workload phổ biến nhất mà chúng ta tìm thấy ngày nay và có lẽ là loại có nhiều buzzword nhất. Chúng được gọi là các workload Big Data. Workload nặng về dữ liệu là loại workload phù hợp cho các gói phần mềm như Hadoop hay MapReduce. Chúng ta phân phối dữ liệu cho một bài toán cụ thể trên nhiều CPU để giảm thời gian thực hiện chúng. Công việc tương tự có thể được thực hiện trên từng data segment, mặc dù không phải lúc nào cũng như vậy. Đây thực chất là sự nghịch đảo của workload nặng về bộ nhớ trong việc di chuyển nhanh chóng dữ liệu đến và đi từ các ổ đĩa quan trọng hơn vấn đề kết nối. Loại bài toán đang được giải quyết trong các workload này thường là trong lĩnh vực Life Science (genomics) hay lĩnh vực nghiên cứu và có phạm vi rộng trong các ứng dụng thương mại, đặc biệt là xung quanh dữ liệu người dùng và sự tương tác.
Các workload cần đến thông lượng cao
Các công việc xử lý hàng loạt (các công việc có các hoạt động gần như không đáng kể để thực hiện song song cũng như các công việc có ít hoặc không có giao tiếp giữa các CPU) được coi là workload nặng về thông lượng cao. Trong workload thông lượng cao, chúng ta tập trung vào thông lượng trong một khoảng thời gian nhất định hơn là hiệu năng xử lý đối với bất kỳ bài toán nào. Chúng ta phân phối nhiều bài toán một cách độc lập trên nhiều CPU để giảm thời gian thực hiện tổng thể. Những workload này cần:
- Chia thành các phần độc lập một cách tự nhiên
- Có rất ít hoặc không có giao tiếp CPU-CPU
- Được thực hiện trong các process hoặc thread riêng biệt trên một CPU (một cách đồng thời)
Workload nặng về xử lý có thể được chia thành các workload nặng về thông lượng cao, tuy nhiên, các workload thông lượng cao không nhất thiết chúng đòi hỏi nhiều về CPU.
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI
- NVIDIA GB200 NVL72: Tối đa hóa đào tạo và suy luận LLM với hàng nghìn tỷ tham số