
Bài viết này sẽ nhấn mạnh tại sao cần phải tập trung vào việc tối ưu hóa cơ sở hạ tầng để có thể đẩy mạnh hiệu suất cho các workload AI và Machine Learning thành công.
Những năm gần đây chúng ta đã chứng kiến sự bùng nổ trong việc tạo ra dữ liệu từ rất nhiều nguồn khác nhau: các thiết bị được kết nối, IoT, các hệ thống phân tích, lĩnh vực chăm sóc sức khỏe, điện thoại thông minh,… Trên thực tế, tính đến năm 2016, 90% của tất cả dữ liệu đã từng được tạo ra là từ hai năm gần nhất phát sinh ra! Để thu nhận được các ý nghĩa chuyên sâu từ tất cả các dữ liệu này mang đến cơ hội to lớn cho các doanh nghiệp, tổ chức để tiếp tục khai thác kinh doanh, mở rộng nhanh hơn sang các thị trường mới, để tiến hành nghiên cứu về lĩnh vực chăm sóc sức khỏe hoặc khí hậu – đó chỉ là một vài ví dụ. Tuy nhiên, sự cấp thiết của việc quản lý lượng dữ liệu khổng lồ, cùng với nhu cầu cần phải nhanh chóng thu nhận những hiểu biết sâu sắc từ chúng, là điều mà chúng ta có thể cảm nhận được. Theo Gartner, các tổ chức báo cáo sự tăng trưởng dữ liệu phi cấu trúc là hơn 50% mỗi năm, đồng thời, một cuộc khảo sát của Accdvisor cho thấy 79% giám đốc điều hành doanh nghiệp đồng ý rằng việc không trích xuất các giá trị và hiểu biết sâu sắc từ dữ liệu này có thể sẽ dẫn đến sự suy tàn cho doanh nghiệp của họ vì mất khả năng cạnh tranh. Vấn đề quản lý dữ liệu này đặc biệt quan trọng trong lĩnh vực trí tuệ nhân tạo (AI) và các workload cho Machine Learning khi có cả yêu cầu sức mạnh xử lý rất lớn và nhu cầu lưu trữ lượng dữ liệu khổng lồ mà chúng sẽ được phân tích dưới dạng nào đó.

Các nền tảng lưu trữ kế thừa sẽ không thể theo kịp

Sự tăng trưởng của dữ liệu khiến các tổ chức CNTT chịu áp lực rất lớn để luôn phản ứng với các doanh nghiệp của họ. Để đối phó với sự tăng trưởng dữ liệu phi cấu trúc này, nhiều tổ chức đã chuyển sang sử dụng các hệ thống lưu trữ mở rộng, nơi có thể mở rộng dung lượng bằng cách thêm các thiết bị được kết nối mới, nhưng vẫn chưa giải quyết được thách thức về hiệu suất để đối phó với tăng trưởng và truy cập dữ liệu của dữ liệu đó một cách nhanh chóng. Gartner cũng tuyên bố rằng vào năm 2022, hơn 80% dữ liệu doanh nghiệp sẽ được lưu trữ trong các hệ thống lưu trữ mở rộng trong các trung tâm dữ liệu đám mây và doanh nghiệp, tăng từ 40% vào năm 2018. Tuy nhiên, lưu trữ kế thừa được thiết kế để giải quyết các vấn đề của ngày hôm qua và không thể xử lý vấn đề không lường trước hiện đang gặp phải với khối lượng công việc mới. Họ không thể cung cấp dữ liệu vào tài nguyên tính toán đủ nhanh, dẫn đến lãng phí thời gian tính toán cho CPU hoặc GPU đắt tiền, họ cũng không thể mở rộng tới petabyte dung lượng khi hiệu suất được tính. Quản lý siêu dữ liệu cũng trở thành một vấn đề khi xử lý hàng tỷ file trong một tập dữ liệu.
Điều này thường được gọi là một “sắc thuế” về hiệu suất của doanh nghiệp. Để theo kịp sự gia tăng mạnh mẽ về hiệu suất và yêu cầu về năng lực xử lý, các tổ chức phải đầu tư mạnh vào cơ sở hạ tầng nhiều hơn – tăng chi tiêu vốn đầu tư (CapEx) cũng như sự phức tạp trong quản lý.
Các kiến trúc sư về lưu trữ và dữ liệu phải đối mặt với ba thách thức chính trong việc phục vụ các yêu cầu mới này:
Làm cho trung tâm dữ liệu linh hoạt hơn
Như đã đề cập, sự kết hợp giữa quy mô ngày càng tăng của dữ liệu và tính cấp bách ngày càng tăng của các tổ chức để hiểu rõ hơn về chúng, tạo ra những thách thức với việc lưu trữ, bảo vệ và xử lý dữ liệu này. Hệ thống lưu trữ kế thừa thiếu chức năng quản lý và hiệu suất để giữ cho dữ liệu sẵn sàng và có thể chia sẻ giữa các workload chính. Trong các kịch bản này, dữ liệu có xu hướng được lưu trữ trong các đảo dữ liệu hoặc silo, khiến cho việc sử dụng các workflow của Machine Learning hiện đại trở nên rất tốn kém và mất thời gian.
Tăng tốc chuyển đổi dữ liệu cho các AI và Machine Learning workload
Các workload phân tích hiện đại – cụ thể là Machine Learning và Deep Learning – đã chuyển đổi cách sử dụng dữ liệu trong các tổ chức. Các khối lượng công việc mới này đòi hỏi các tập dữ liệu cực lớn, truy cập nhanh hơn và song song hơn vào dữ liệu đó và các thuật toán để đào tạo mở đường cho việc học.
Tuy nhiên, các giải pháp lưu trữ kế thừa không thể tận dụng các mạng băng thông cao hiện nay, vì vậy các tổ chức đã chuyển sang các file system song song cung cấp cấu hình hiệu suất cao hơn nhiều và hỗ trợ nhiều loại dữ liệu có thể giúp hợp lý hóa quá trình chuẩn bị dữ liệu để sử dụng trong AI / Khối lượng công việc ML.
Tối ưu hóa đầu tư vào cơ sở hạ tầng
Cuối cùng, liên quan đến “sắc thuế” về hiệu suất của Wap, các tổ chức muốn tối ưu hóa khoản đầu tư của họ vào cơ sở hạ tầng GPU và / hoặc CPU có giá trị cao thường được yêu cầu trong các Machine Learning và AI workload. Việc các tài nguyên này không hoạt động hoặc không được sử dụng đúng mức sẽ mang lại tác động thực sự nếu cơ sở hạ tầng lưu trữ bên dưới không thể giữ dữ liệu được đưa đến chúng.
Các giải pháp lưu trữ mới sẽ có thể loại bỏ nút cổ chai I / O này, tận dụng mạng hiệu suất cao hơn (chẳng hạn như 100GbE hoặc InfiniBand) và giữ cho các GPU và CPU luôn ‘khao khát’ I/O này được tiếp tế. Điều này sẽ giúp các tổ chức tránh các khoản đầu tư lớn vào cơ sở hạ tầng và giảm “sắc thuế” kia.
WekaIO có thể giúp giải quyết các vấn đề lớn
WekaIO đã tạo được dấu ấn với cách tiếp cận mới về lưu trữ giúp giải quyết những vấn đề không lường trước được này với khối lượng công việc đòi hỏi nhiều dữ liệu và hiệu suất. Hệ thống tệp Weka là một giải pháp lưu trữ mở rộng dựa trên phần mềm được tối ưu hóa cho khối lượng công việc hiệu suất cao như AI, ML và phân tích.
Các giải pháp lưu trữ kế thừa không thể tận dụng các mạng băng thông cao hiện nay, vì vậy các tổ chức đã chuyển sang các file system song song cung cấp cấu hình hiệu suất cao hơn nhiều và hỗ trợ nhiều loại dữ liệu có thể giúp hợp lý hóa quy trình chuẩn bị dữ liệu để sử dụng trong các workload AI / ML .
Weka cung cấp sự đơn giản của lưu trữ kế thừa, nhưng nó mang lại hiệu suất cao hơn tất cả – lưu trữ flash, khả năng mở rộng đám mây và quản lý đơn giản hóa không bao giờ được hình dung bởi các nhà cung cấp sản phẩm khác. Trong môi trường sản xuất, WekaIO đã cho thấy hiệu suất của hệ thống NAS truyền thống gấp 10 lần với quy mô tuyến tính khi cơ sở hạ tầng phát triển.
Cách thức hoạt động của Weka
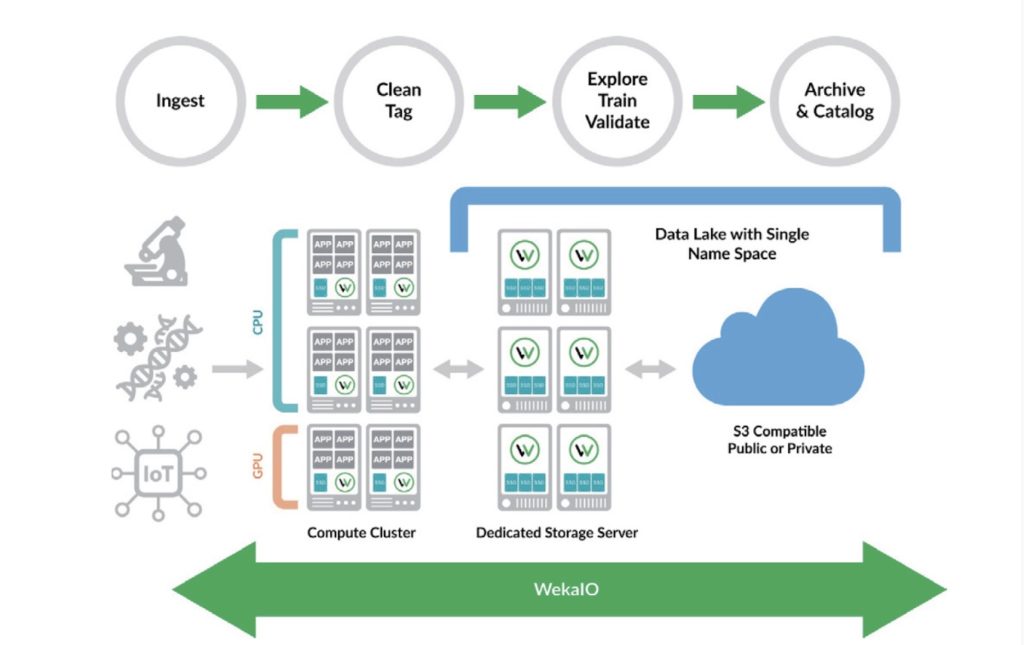
Weka đã xây dựng một nền tảng phần mềm hiệu suất cao phân tán, có thể mở rộng, kết nối nhiều máy chủ với các ổ đĩa trạng thái rắn gắn liền cục bộ vào một không gian tên toàn cầu tuân thủ POSIX để quản lý hiệu suất và đơn giản hóa. Phần mềm được triển khai trên các máy chủ thương mại tiêu chuẩn cung cấp tính độc lập phần cứng thực sự và chi phí tốt nhất. Phần mềm hỗ trợ phân tầng nội bộ cho bất kỳ giải pháp lưu trữ đối tượng S3 có sẵn trên thị trường, mang lại khả năng mở rộng lớn và tính kinh tế tuyệt vời cho một danh mục dữ liệu ngày càng phát triển. Biểu đồ dưới đây cung cấp một cái nhìn tổng quan về kiến trúc của một triển khai điển hình cho môi trường học tập sâu.
Khối lượng công việc hiệu suất cao ngày nay đòi hỏi một cơ sở hạ tầng lưu trữ hiện đại, mang lại hiệu suất, khả năng quản lý, khả năng mở rộng và hiệu quả chi phí được yêu cầu trong kỷ nguyên chuyển đổi dữ liệu, biến dữ liệu của công ty thành giá trị thực cho doanh nghiệp. Lưu trữ kế thừa, chẳng hạn như NAS và các hệ thống tệp song song được thiết kế trong kỷ nguyên đĩa, đơn giản là sẽ không đạt được mục đích.
Bài viết liên quan
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI
- NVIDIA GB200 NVL72: Tối đa hóa đào tạo và suy luận LLM với hàng nghìn tỷ tham số