
Khi bàn đến các máy chủ tăng tốc GPU, có thể nói hệ thống DGX-2 của Nvidia rất khó bị đánh bại. 16 GPU V100 của nó được hàn lại cùng với kết nối NVLink cung cấp 2 petaflops hiệu năng tensor floating point hoặc 125 teraflops hiệu năng double precision. Cung cấp cho các GPU đó là một nửa terabyte bộ nhớ HBM2 xếp chồng lên nhau có thể cung cấp tới 16 TB mỗi giây. Nhưng nếu bạn muốn kết nối nhiều máy chủ DGX-2 với nhau và chạy khối lượng công việc nặng về I/O thông qua cụm đó, bạn sẽ cần một số phần cứng và phần mềm bổ sung để đảm bảo các GPU đó không bị thiếu dữ liệu giữa chừng.
Về cơ bản, đó là vì DGX-2 được thiết kế theo kiến trúc scale-up (nâng cấp) chứ không phải scale-out (mở rộng). Điều đó có nghĩa là có một nút thắt cổ chai dữ liệu cố hữu vào và ra khỏi máy chủ đó. May mắn thay, một số thứ cần thiết để cụm DGX-2 giải quyết với mức I/O cao hiện đã có: Card giao tiếp Mellanox NIC, cung cấp phần cứng giao tiếp mạng hiệu suất cao và hỗ trợ RDMA; GPUDirect, công nghệ RDMA hỗ trợ đường kết nối dữ liệu trực tiếp giữa GPU và các thiết bị ngang hàng qua PCI-Express; Thư viện Nvidia Collective Communications Library (NCCL), một package cung cấp khả năng giao tiếp được tối ưu hóa cho các thiết lập đa GPU và đa node; và GPUDirect Storage, thiết lập đường kết nối trực tiếp giữa bộ nhớ GPU và storage. (Trên thực tế, GPUDirect Storage hiện chỉ khả dụng cho những khách hàng đăng ký sớm và dự kiến sẽ có mặt rộng rãi hơn trong nửa đầu năm 2020).

Phần còn thiếu cho đến bây giờ là một lớp phần mềm kết hợp tất cả các yếu tố này lại với nhau và cung cấp khả năng tăng tốc I/O của hệ thống lưu trữ cho các ứng dụng GPU được scale-out ở quy mô lớn. Tại SC19 tuần này, Giám đốc điều hành của Nvidia, Jensen Huang, đã công bố một con mãnh thú như vậy, mà công ty gọi là Magnum IO. Về cơ bản, đây là bộ phần mềm cung cấp API được thiết kế để giải tỏa nút cổ chai I / O cho các máy chủ đa GPU này. Theo Huang, Magnum IO là một trong những điều lớn nhất chúng tôi đã làm trong năm qua. Lí thuyết hợp lý cho tuyên bố đó là rất ít công nghệ khác mà họ đã phát triển gần đây có thể tăng tốc khối lượng công việc tăng tốc GPU lên mức độ này – lên đến 20X trong một số trường hợp.
Bộ phần mềm mới này nhằm vào các nhà khoa học và nhà nghiên cứu dữ liệu đang xử lý các bộ dữ liệu lớn sử dụng trong trí tuệ nhân tạo và các ứng dụng điện toán hiệu năng cao khác. Để giải quyết vấn đề đó, Magnum IO giao tiếp với ngăn xếp phần mềm CUDA-X của Nvidia, cung cấp khả năng tăng tốc GPU trên một loạt các gói AI và HPC thường được sử dụng.
Là một vấn đề thực tế, hệ thống lưu trữ và tập tin bên ngoài cũng phải giữ kết thúc của món hời hiệu suất. Các đối tác lưu trữ ban đầu bao gồm DataDirect Networks, Excelero, IBM Spectrum, Pure Storage và WekaIO, mang đến cho bạn cảm giác về mức độ hiệu năng lưu trữ mà Nvidia có trong tâm trí. Ý tưởng chung là tận dụng lợi thế của việc lưu trữ không bay hơi (đặc biệt là NVM-Express), độc lập hoặc trong các loại vải mạng.
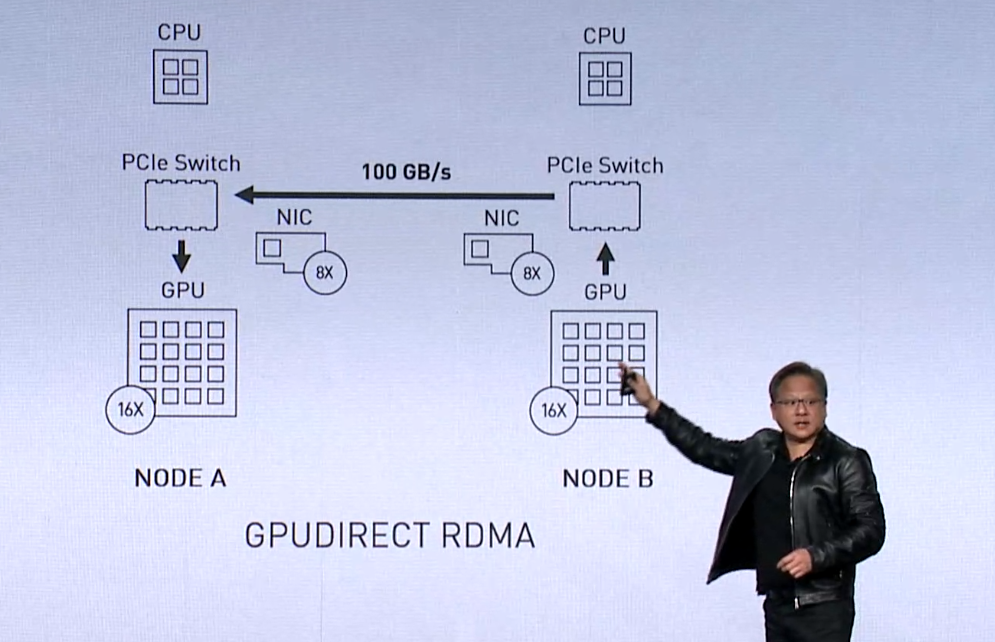
Ở cấp độ phần cứng, băng thông dữ liệu cần thiết được phân phối bằng cách trang bị máy chủ GPU với rất nhiều NIC nhanh, trong trường hợp Huang mô tả, sử dụng tám bộ điều hợp Mellanox 100Gbps cho mỗi máy chủ DGX-2. Có lẽ, Magnum IO sẽ hoạt động với các loại máy chủ đa GPU khác, do Nvidia đã liệt kê Cray / HPE, Dell EMC, IBM, Lenovo, Inspur, Penguin Computing, Atos và Supermicro, với tư cách là đối tác của Magnum IO OEM. Huang cũng đề cập rằng họ đang xem xét các nhà cung cấp NIC khác ngoài Mellanox, nhưng không rõ anh ta có ý định gì.
Thiết lập 8-NIC DGX-2 mà anh ta sử dụng làm ví dụ cung cấp một băng thông khổng lồ 100 GB/giây đến và đi từ máy chủ. Băng thông đó là thứ tự của băng thông bộ nhớ trên CPU, ông Huang Huang chỉ ra.
Magnum IO cũng có thể được xếp lớp bên dưới RAPIDS, ngăn xếp khoa học dữ liệu được tăng tốc của Nvidia mà chúng tôi đã báo cáo vào năm ngoái . Thuận tiện, bộ phần mềm này cũng hỗ trợ cấu hình đa GPU, đa nút. Nó đã được sử dụng tại một số địa điểm nổi bật của HPC, bao gồm Phòng thí nghiệm quốc gia Oak Ridge, NASA, Trung tâm siêu máy tính San Diego và Phòng thí nghiệm Berkeley.
Áp dụng Magnum IO cho số liệu TPC-H, điểm chuẩn hỗ trợ quyết định được sử dụng để đo hiệu suất truy vấn trên cơ sở dữ liệu 10TB, tăng tốc độ thực thi theo hệ số 20. Trên ứng dụng sinh học cấu trúc trong thế giới thực bằng gói Visual Phân tích động học (VMD), Magnum IO tăng hiệu năng thời gian chạy lên gấp 3 lần.
Magnum IO cũng đã được sử dụng để tăng tốc trực quan hóa Mars Lander, mà Huang tuyên bố là trực quan hóa khối lượng tương tác lớn nhất thế giới. Trong thiết lập này, bốn máy chủ DGX-2, có khả năng truyền dữ liệu với tốc độ 400 GB / giây, đã được sử dụng để ăn 150 TB dữ liệu mô phỏng.

Với các loại ứng dụng được phối hợp bởi Magnum IO, Nvidia đã phát triển một kiến trúc tham chiếu các loại, mà Huang gọi là “supercomputing analytics Instrument”. Ở dạng ban đầu, nó bao gồm một máy chủ DGX-2 được trang bị tám Mellanox 100Gbps NIC và 30 TB ổ lưu trữ NVM-Express. Nvidia dường như không bán một hệ thống như vậy vào thời điểm này (ít nhất, không có giá nào được đưa ra), mặc dù có lẽ người ta có thể lắp ráp một hệ thống như vậy mà không gặp quá nhiều khó khăn. Một lần nữa, chúng tôi nghĩ rằng giả định ở đây là các đối tác OEM của Nvidia sẽ tiếp nhận điều này và cung cấp các phiên bản của riêng họ.
Các hệ thống này sẽ không hề rẻ – một máy chủ DGX-2 chưa được bán lẻ có giá 399.000 USD – nhưng nếu bạn đang tìm kiếm khả năng tăng tốc GPU được scale-out và bạn có bộ dữ liệu lớn để sử dụng, điều này có thể phù hợp với cái bill phải trả. Chúng tôi hy vọng Nvidia sẽ nói nhiều hơn về các công nghệ này trong tương lai.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là đối tác NPN cấp Elite (2022) chính thức của NVIDIA cho các hệ thống DGX (DGX A100, DGX Station A100) và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là đối tác NPN cấp Elite (2022) chính thức của NVIDIA cho các hệ thống DGX (DGX A100, DGX Station A100) và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Hướng dẫn build một cụm GPU cho AI
- GDDR6 vs HBM – Định nghĩa các loại bộ nhớ GPU
- NVIDIA Omniverse ft Apple Vision Pro: Mở rộng thế giới quan với VR/AR
- Tôi có cần CPU kép không?
- NVIDIA NIM: Vi dịch vụ suy luận tối ưu hóa cho triển khai mô hình AI quy mô lớn