
Nhiều ứng dụng thương mại của Deep Learning cần hoạt động ở quy mô lớn, điển hình là hình thức phục vụ các mô hình đã triển khai cho số lượng lớn khách hàng. Tuy nhiên suy luận chỉ là một nửa của trận chiến. Mặt khác của vấn đề này, mà chúng tôi sẽ giải quyết ở đây, là làm thế nào để mở rộng quy mô xây dựng mô hình ML và nỗ lực nghiên cứu khi các tập dữ liệu đào tạo phát triển rất lớn và đào tạo phải được thực hiện theo kiểu phân tán trên đám mây. Tại Intuition Machines, chúng tôi thường cần xử lý các bộ dữ liệu quy mô web về hình ảnh và video, và như vậy, việc có một nền tảng đào tạo phân tán đa người dùng hiệu quả, có thể mở rộng là điều cần thiết.
Bài đăng này tóm tắt đánh giá gần đây của chúng tôi về lĩnh vực này và nhằm mục đích giới thiệu các nguyên tắc đào tạo trên quy mô lớn cùng với tổng quan ngắn gọn về các giải pháp nguồn mở tốt nhất hiện có để đào tạo mạng của riêng bạn theo cách này.
Thách thức đối với việc mở rộng quy mô cho Deep Learning là gì?
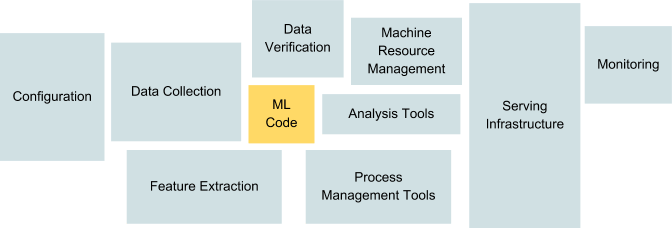

Khi các dự án ML chuyển từ điều tra nghiên cứu quy mô nhỏ sang triển khai trong thế giới thực, cần phải có một lượng lớn cơ sở hạ tầng để hỗ trợ suy luận quy mô lớn, đào tạo phân tán hiệu quả, đường ống nhập / chuyển đổi dữ liệu, lập phiên bản, thử nghiệm tái tạo, phân tích và giám sát; tạo và quản lý các dịch vụ và công cụ hỗ trợ này cuối cùng có thể tạo thành phần lớn khối lượng công việc của các kỹ sư ML, nhà nghiên cứu và nhà khoa học dữ liệu.
Phần mã ML trong hệ thống ML thế giới thực nhỏ hơn rất nhiều so với cơ sở hạ tầng cần thiết để hỗ trợ nó.
Nguồn: Sculley và cộng sự: “Nợ kỹ thuật ẩn trong hệ thống máy học”
Làm thế nào chúng ta có thể cho phép các nhóm này tập trung vào việc đào tạo các mô hình tốt nhất và cung cấp các giải pháp tốt nhất mà không phải đổi mới bánh xe mỗi lần hoặc sa lầy vào nợ kỹ thuật? ( Sculley và cộng sự thảo luận về một số thách thức khác trong việc mở rộng hệ thống ML, chẳng hạn như Mã keo, Rừng đường ống, Khả năng tái tạo và Nợ quản lý quy trình). Chúng ta sẽ xem xét một số giải pháp cơ sở hạ tầng mới nổi để chống lại những vấn đề này dưới đây.
Ngày nay, người ta thường sử dụng các dịch vụ điện toán đám mây như Amazon AWS, Microsoft Azure hoặc Google GCP để xử lý tất cả các loại khối lượng công việc. Về mặt suy luận và xử lý dữ liệu, chúng tôi có thể xử lý hiệu quả các công việc lớn song song bằng cách sử dụng các cụm nút công nhân và dịch vụ được phối hợp với Kubernetes. Chúng ta có thể không biết về phần cứng cơ bản và triển khai trên các nền tảng khác nhau, sử dụng container hóa để quản lý các yêu cầu cài đặt.
Đối với đào tạo, các gói Deep Learning như TensorFlow và PyTorch đã thêm hỗ trợ gốc cho đào tạo đa GPU. Điều này có thể đủ đơn giản để triển khai ở quy mô nhỏ trên phần cứng chuyên dụng, nhưng khi xử lý đào tạo phân tán nhiều nút thì cần phải làm thêm. Một yêu cầu lớn khác là tính di động: cùng một mã phải chạy trên máy tính xách tay, thiết bị GPU hoặc một cụm và thậm chí tự động thay đổi tỷ lệ dựa trên nhu cầu. Có thể tạo thủ công các tập lệnh để sắp xếp việc triển khai trên một cụm, nhưng điều này rất phức tạp. Tuy nhiên, hiện nay đã có các giải pháp mã nguồn mở cho phép đóng gói, đóng gói và triển khai tự động và điều phối công nhân và việc làm. Chúng ta sẽ xem xét một số trong phần tiếp theo.
Ngoài đào tạo phân tán của một mô hình duy nhất, có những yêu cầu khác để tạo ra một hệ thống pipelined thực sự hiệu quả, có thể lặp lại và linh hoạt cho toàn bộ quy trình ML. Khi các nhà nghiên cứu đang giải quyết các vấn đề mới và điều tra các mô hình mới, cần có cơ sở hạ tầng hỗ trợ một số nhiệm vụ này để hợp lý hóa quy trình:
- Nhập dữ liệu, phân phối, lập phiên bản, tiền xử lý, phân tách, chuyển đổi / tăng cường
- Đóng gói và triển khai công việc; khả năng tái tạo công việc
- Giám sát thử nghiệm / ghi nhật ký; so sánh kết quả qua các lần chạy, bảng điều khiển trạng thái
- Tự động điều chỉnh siêu tham số và tìm kiếm kiến trúc mô hình
- Triển khai nhanh chóng từ đào tạo đến phục vụ / suy luận mô hình trực tuyến và thử nghiệm A / B
- Hỗ trợ nhiều khuôn khổ Học tập sâu và các thư viện khác theo cách tích hợp, để tránh áp đặt giới hạn cho các nhà nghiên cứu cho phép các giải pháp đa dạng được thử
Nhìn chung, mục tiêu là lặp lại và tìm kiếm trên nhiều phương pháp, mô hình, tính năng và đường ống dữ liệu theo cách có thể quản lý, lặp lại và đo lường được, thay vì tin tưởng vào các phương pháp tiếp cận đặc biệt phổ biến đối với nhiều phòng nghiên cứu nhỏ. Lý tưởng nhất là sau khi chúng tôi đã thiết lập các quy trình để quản lý các thành phần này, toàn bộ quy trình trở nên đơn giản để các nhà nghiên cứu hoặc nhà khoa học dữ liệu sử dụng các môi trường được triển khai theo cách tự phục vụ và cộng tác chia sẻ một nhóm tài nguyên chung của các nút cụm.
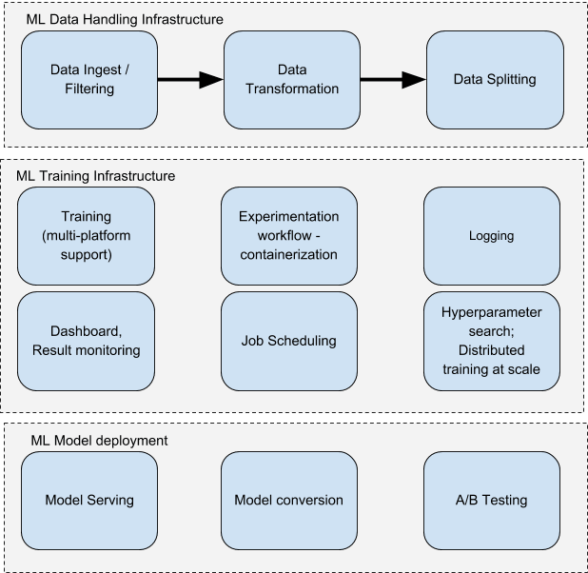
Một số thành phần kiến trúc cốt lõi của quy trình làm việc ML.
Có một số lượng lớn các giải pháp thương mại đang được chào mời để quản lý vòng đời ML, chẳng hạn như RiseML, H20 Driverless, Anaconda Enterprise, Databricks, Paperspace, Domino Data Lab, ParallelM, neptune.ml và comet.ml. Nhiều nền tảng trong số này cũng được xây dựng xung quanh Kubernetes. Ngoài ra còn có các nền tảng được lưu trữ hữu ích trên các dịch vụ đám mây công cộng lớn, chẳng hạn như Dịch vụ Máy học Azure của Microsoft (trước đây là BatchAI), SageMaker của Amazon và Cloud AI của Google, giúp giải quyết một số yêu cầu này.
Nhiều tổ chức lớn cũng đã phát triển các giải pháp nội bộ riêng cho những vấn đề này, ví dụ FBLearner Flow (Facebook) , MichelAngelo (Uber) , TFX (Google) .
Tuy nhiên, chúng tôi rất hâm mộ nguồn mở (có các phần nguồn mở của hệ thống hCaptcha và giao thức HUMAN của chúng tôi ) và đóng góp vào hàng chục dự án mã nguồn mở mà chúng tôi sử dụng nội bộ. Do đó, thay vì sử dụng một dịch vụ thương mại được lưu trữ hoặc tự phát triển từ đầu, sở thích của chúng tôi là xem những giải pháp tương đương nguồn mở nào đang xuất hiện trong không gian cơ sở hạ tầng ML. Ở đây có nhiều yêu cầu khác nhau có thể được xử lý bởi một gói duy nhất hoặc kết hợp nhiều yêu cầu, mà chúng tôi sẽ mô tả tiếp theo.
MỘT SỐ GIẢI PHÁP HẠ TẦNG NGUỒN MỞ ML
Mô hình máy tính xách tay Jupyter đã trở nên phổ biến trong các nhà nghiên cứu và nhà khoa học dữ liệu để lặp lại nhanh chóng mã (đặc biệt là Python), hiển thị kết quả và thử nghiệm với các mô hình khác nhau. JupyterHub cho phép lưu trữ nhiều người dùng với máy chủ sổ ghi chép của riêng họ; nó được thiết kế để linh hoạt, có thể mở rộng và di động, đồng thời có thể được triển khai với Kubernetes.
Một dự án khởi nguồn từ Google, Kubeflow bắt đầu với mục đích giúp dễ dàng thực hiện các công việc TensorFlow trên Kubernetes và đang mở rộng để hỗ trợ toàn bộ các công cụ ML và cơ sở hạ tầng khác. Bao gồm các:
- TFJob – một thông số tài nguyên / tệp YAML mô tả cách chạy một công việc TensorFlow (có thể được phân phối) trên Kubernetes
- Argo – Xây dựng luồng công việc gốc vùng chứa trên Kubernetes (mỗi bước của quy trình làm việc là một vùng chứa). Ví dụ: xây dựng các thùng chứa có thể tái sử dụng tự động từ các mô hình được đào tạo.
- Seldon-core – triển khai mô hình qua Docker; chuyển đổi sang microservices với API REST / gRPC; Thử nghiệm A / B; và quản lý suy luận được triển khai theo quy mô.
- TF Serving – một thư viện khác phục vụ các mô hình để suy luận, thử nghiệm A / B, lập phiên bản mô hình
- Istio – chỉ số, thử nghiệm A / B và tích hợp với phân phát TF
- Katib – Điều chỉnh siêu thông số Hộp đen, trong mạch của Google Vizer
- Ksonnet được sử dụng thay thế cho Helm để quản lý gói Kubernetes.
Ở cấp khung Deep Learning, Kubeflow đã và đang bổ sung hỗ trợ cho MXNet, PyTorch và Chainer cũng như TensorFlow. Jupyterhub cũng có sẵn như một thành phần.
Rõ ràng có một số lượng lớn các thành phần riêng biệt thực sự là các dự án độc lập, với một số chồng chéo và một số lỗ hổng. Dự án Kubeflow, mặc dù ít nhiều có thể sử dụng được tại thời điểm viết bài, vẫn đang được phát triển nặng và đòi hỏi đầu tư lớn về thời gian kỹ thuật để hiểu hệ thống, cấu hình nó theo nhu cầu của bạn và thường vá một số khu vực bạn cần nhưng không có ai. gần đây đã đề cập đến việc tận dụng tối đa mọi thứ theo cách tích hợp thực sự và hỗ trợ nhiều người dùng một cách linh hoạt.
Quan điểm của chúng tôi là có rất nhiều tầm nhìn ở đây và hy vọng các mảnh ghép sẽ nhanh chóng kết hợp với nhau khi dự án phát triển. Tuy nhiên, đối với các tổ chức lớn hơn có chuyên môn về hệ thống phân tán, nó mang lại ít lợi ích hơn bạn có thể mong đợi do sự chưa trưởng thành của cơ sở mã và tình trạng hỗn loạn nặng nề. Nếu không có nhân viên bảo trì Kubeflow, việc sử dụng nó cho những công việc không tầm thường có thể khó biện minh và chắc chắn sẽ đòi hỏi đầu tư thời gian đáng kể.
Một nền tảng tích hợp khác được xây dựng trên Kubernetes, nhấn mạnh vào ML có thể tái tạo trên quy mô lớn, theo cách đơn giản và dễ tiếp cận. Nó có phần phù hợp hơn với các mục tiêu của một hệ thống nhiều người dùng tự phục vụ, quan tâm đến việc lập lịch và quản lý công việc để tận dụng tốt nhất các tài nguyên cụm sẵn có. Nó cũng xử lý lập phiên bản mã / mô hình, tự động tạo và triển khai hình ảnh docker và có thể hỗ trợ tự động điều chỉnh tỷ lệ.
Nó cung cấp các tính năng như đào tạo mô hình phân tán, thử nghiệm, bảng điều khiển với trực quan hóa, số liệu và tối ưu hóa siêu tham số dễ dàng. Polyaxon hỗ trợ nhiều khung công tác DL bao gồm Tensorflow, Keras, MXNet, Caffe, PyTorch. Hiện tại không có hỗ trợ tích hợp nào cho việc phân phát mô hình, tập trung nhiều hơn vào thử nghiệm và suy luận, nhưng các tính năng mới đang được bổ sung nhanh chóng.
So với Kubeflow, Polyaxon rất tập trung. Polyaxon không cố gắng bao gồm việc phân phát thời gian thực, tích hợp istio, không có yêu cầu ksonnet và không bị ràng buộc chặt chẽ với seldon. Thay vì polyaxon tập trung hơn vào việc chạy các thử nghiệm adhoc hoặc lặp lại. Nó xử lý tất cả việc quản lý gói và có thể tự động hóa cài đặt notebook và tensorboard. Polyaxon giải quyết vấn đề chạy các công việc khác nhau trên cùng một cụm và nó cũng hỗ trợ đào tạo phân tán. Nó có một bảng điều khiển quản lý công việc được tích hợp sẵn, cũng như quản lý người dùng đơn giản.
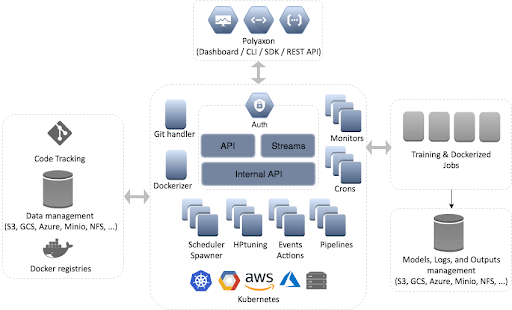
Polyaxon nằm trên các dịch vụ Kubernetes để cung cấp nền tảng đào tạo và thử nghiệm ML dễ sử dụng, có thể lặp lại, hỗ trợ bảng điều khiển, lập phiên bản và hơn thế nữa.
Nguồn: https://docs.polyaxon.com/experimentation/concept/
IBM’s Fabric for Deep Learning (phát âm là “fiddle”) là một nền tảng dựa trên Kubernetes được thiết kế xoay quanh đào tạo phân tán dựa trên đám mây, đàn hồi và trừu tượng hóa một số sự phức tạp của cơ sở hạ tầng cơ bản để hướng tới “Học sâu như một dịch vụ”. Nó hỗ trợ nhiều khung công tác DL chính – Tensorflow, Keras, Caffe 1 & 2 và Torch, đồng thời sử dụng Jupyter, Docker và Helm, đồng thời được thiết kế dựa trên dữ liệu và lưu trữ mô hình dựa trên S3. Nó cung cấp một bảng điều khiển Grafana để theo dõi công việc và có thể sử dụng Horovod để đào tạo phân tán. Tệp kê khai được sử dụng để mô tả một mô hình sẽ được đào tạo, siêu tham số, yêu cầu tài nguyên, số liệu, v.v. API REST được sử dụng để giao tiếp với gRPC Trainer, nơi lưu trữ các công việc trong cơ sở dữ liệu và xử lý việc lập lịch trình đào tạo nhiều người dùng trong suốt cuộc đời của họ chu kỳ, cũng như máy chủ tham số. Có một dịch vụ dữ liệu đào tạo để quản lý số liệu và nhật ký. Để triển khai mô hình, tích hợp với Seldon được hỗ trợ.
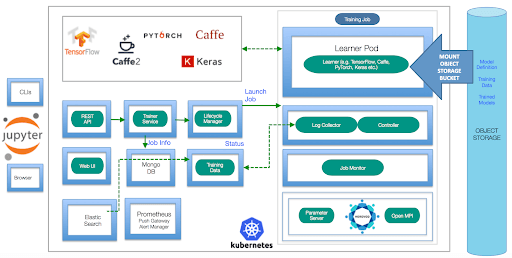
Kiến trúc của FfDL
Nguồn: https://github.com/IBM/FfDL
Framework python này gần đây đã được Instacart lấy nguồn mở và là một giải pháp quy trình làm việc dễ sử dụng hơn cho hệ thống đào tạo và suy luận ML. Nó hỗ trợ tìm kiếm siêu tham số, trích xuất dữ liệu, mã hóa và chia nhỏ đường ống, kết nối cơ sở dữ liệu, quản lý phụ thuộc, kiểm tra CI / CD, triển khai mô hình và tích hợp với các gói như Keras, Tensorboard, Scikit-learning và Jupyter. Một ý tưởng chính là chuẩn hóa thực hành ML trên các thư viện khác nhau, với một tập hợp các trình bao bọc. Có lẽ tập trung vào dữ liệu chuỗi thời gian / văn bản nhiều hơn là video và hình ảnh và Deep Learning dựa trên mô hình CNN, và nó không đi vào thế giới của việc chứa và quản lý cụm.
Do đó, có lẽ đây là một điểm khởi đầu tốt cho những người mới tham gia vào lĩnh vực này, những người đang tìm kiếm một số giải pháp quy trình làm việc và tính nhất quán mà chúng tôi đã mô tả, nhưng nó có lẽ thiếu một số tính năng nâng cao hơn hữu ích cho một tổ chức đang phân phối quy mô lớn đào tạo và tìm kiếm kiến trúc trên dữ liệu miền trực quan.
Một thư viện mã nguồn mở do Databricks tạo ra, được thiết kế để quản lý 3 giai đoạn của vòng đời ML: Theo dõi, Dự án và Mô hình. Mục tiêu của dự án là cải thiện khả năng tái sản xuất và cho phép theo dõi thử nghiệm, đồng thời giúp chuyển mô hình sang sản xuất dễ dàng hơn. Nó cũng được thiết kế để hỗ trợ bất kỳ khung ML dựa trên Python hoặc R, có giao diện người dùng web để giúp theo dõi dễ dàng và có hỗ trợ nhiều người dùng bằng cách chạy một máy chủ theo dõi. Theo dõi hỗ trợ các số liệu, hình ảnh hóa, lưu trữ tạo tác và so sánh các lần chạy, cũng như điều chỉnh siêu tham số. Các dự án hỗ trợ một cách đơn giản để đóng gói mã, chạy các tham số và phụ thuộc thông qua tệp cấu hình YAML và môi trường Conda, và tích hợp với Git. Các dự án cũng hỗ trợ I / O tập dữ liệu có thể mở rộng với các máy chủ như AWS S3. Mô hình có thể dễ dàng được triển khai theo một số cách, bao gồm như một máy chủ REST,
Nhìn chung, thật dễ dàng để bắt đầu với thiết lập cục bộ cho một người dùng duy nhất, nhưng vẫn có khả năng mở rộng để hỗ trợ các nhóm và tập dữ liệu lớn hơn. Tuy nhiên, đào tạo phân tán hoặc hỗ trợ cụm không phải là một phần của chức năng, do đó, công việc bổ sung sẽ được yêu cầu ở đây.
Gói Python này từ Sentient được thiết kế để quản lý các thử nghiệm xây dựng mô hình ML, bao gồm một số ý tưởng tương tự như ML Flow hoặc Lore, mà không cần triển khai, nhưng với một số tích hợp đào tạo dựa trên đám mây. Nó hỗ trợ các gói phổ biến nhất – Keras, TF, PyTorch và scikit-learning. Các tính năng chính của nó bao gồm quản lý môi trường và sự phụ thuộc, giám sát / ghi nhật ký, quản lý thử nghiệm, tìm kiếm siêu tham số, quản lý tạo tác và lưu trữ. Một trong những tính năng độc đáo của nó là nó có tích hợp trực tiếp với API Amazon EC2 và Google Cloud, cũng như tự động mở rộng quy mô để giúp cho việc khởi chạy các công việc đào tạo trên các nền tảng này trở nên dễ dàng.
Airbnb được giới thiệu gần đây thư viện đường ống ML end-to-end mã nguồn mở mới của họ. Tính đến thời điểm viết nó vẫn chưa được phát hành, nhưng có vẻ rất hứa hẹn. Nó bao gồm các tính năng trong toàn bộ quy trình làm việc từ nhập / chuyển đổi dữ liệu, đào tạo, quản lý mô hình, điều chỉnh siêu tham số, giám sát và triển khai. Nó được thiết kế theo mô-đun và hỗ trợ các khung đào tạo ML chung. Có hỗ trợ cho các công cụ chuyển đổi dữ liệu và trực quan hóa dữ liệu được tích hợp sẵn, để trợ giúp một trong những phần của quy trình phát triển ML nơi các nhà nghiên cứu và kỹ sư dành phần lớn thời gian của họ. Môi trường Redspot của nó là một phần mở rộng của JupyterHub giúp quản lý phiên bản và gói, đồng thời được xây dựng xung quanh các dịch vụ vùng chứa Docker tự động, giúp hỗ trợ quy trình đào tạo và môi trường nhiều người dùng. Quản lý mô hình giữ cho mã mô hình và các mô hình được đào tạo đồng bộ, và cải thiện khả năng tái tạo thông qua các chỉ số thông thường. Sản xuất hỗ trợ phát trực tuyến có thể mở rộng và mang lại sự nhất quán giữa môi trường đào tạo và triển khai.
Có rất nhiều hứa hẹn ở đây, mặc dù chúng ta sẽ phải xem mọi thứ hoạt động như thế nào trong thực tế một khi được phát hành.
Dữ liệu
Trên mặt trận nhập, xử lý, quản lý và truy xuất dữ liệu, có rất nhiều thứ có thể được đề cập chi tiết ở đây, về cách xử lý hiệu quả các tập dữ liệu đào tạo khi quy mô của chúng lớn hơn những gì có thể được lưu trữ trên một nút. Hiện tại, chúng tôi đang sử dụng các giải pháp tùy chỉnh trong những lĩnh vực này, nhưng có một vài gói đáng để chỉ ra.
Khả năng chuyển đổi dữ liệu bằng cách sử dụng các đường ống khác nhau là một phần thiết yếu của quá trình ML. Trong thử nghiệm, kỹ thuật dữ liệu thường không quan trọng hơn thiết kế mô hình. Khi các mô hình và dữ liệu phát triển song song, nhiều tổ chức phải đối mặt với vấn đề về khả năng lặp lại và lập phiên bản của các bộ dữ liệu cùng với các mô hình. Nhưng không thể chỉ lưu trữ bộ dữ liệu khổng lồ trong git. Vì vậy, các gói như Pachyderm cho phép xuất xứ dữ liệu, tức là dữ liệu đến từ đâu và nó đã được sửa đổi như thế nào trong quá trình này. Khi dữ liệu được nhập từ các vị trí khác nhau, được làm sạch, tăng cường và chuyển đổi bằng các phương pháp khác nhau, kiểm soát phiên bản có thể được áp dụng, để các thử nghiệm có thể tiết lộ liệu đó là thay đổi đối với tập dữ liệu hoặc đối với mô hình đã gây ra cải tiến. Một số điều này có thể được coi là quá mức cần thiết trong một số quy trình công việc, nhưng với dữ liệu là một phần quan trọng của toàn bộ quy trình ML, chẳng hạn, bạn nên nghĩ cách tích hợp các phương pháp này với theo dõi thử nghiệm. Pachyderm cũng được xây dựng xung quanh Kubernetes và có thể được tích hợp với Kubeflow.
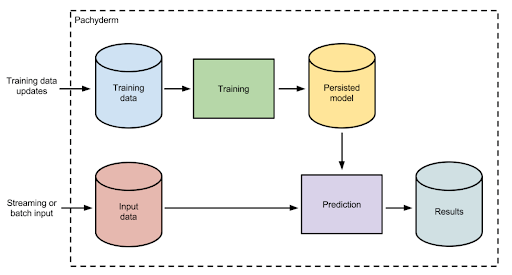
Pachyderm cho phép lập phiên bản dữ liệu và quy trình làm việc mô hình lâu dài.
nguồn http://docs.pachyderm.io/en/latest/cookbook/ml.html
Một thư viện để tăng dữ liệu hình ảnh. Thường cần thiết trong các nhiệm vụ Thị giác máy tính, khả năng áp dụng các phép biến đổi tham số khác nhau cho tập dữ liệu hình ảnh có thể là một điểm nghẽn trong đào tạo. Có thể làm điều này một cách nhanh chóng và có thể phát trực tiếp là một thành phần hữu ích.
Để phù hợp với xu hướng sử dụng các microservices dựa trên Kubernetes và Docker, ý tưởng về Functions as a Service là một cách có thể mở rộng để tạo các đường ống xử lý dữ liệu tùy chỉnh từ các thành phần chức năng hiện có, theo kiểu Serverless. Chúng tôi đã và đang điều tra các cách tiếp cận này và tích hợp với các hệ thống khác; đây dường như là một cách linh hoạt và mạnh mẽ để xử lý các yêu cầu xử lý dữ liệu quy mô lớn cho cả đào tạo và suy luận.
Đào tạo phân tán
Các giải pháp được mô tả cho đến nay giúp quản lý quy trình đào tạo, nhưng việc tận dụng sức mạnh tính toán bổ sung mà một cụm có thể cung cấp để cung cấp kết quả đào tạo nhanh hơn yêu cầu một số thay đổi đối với mã đào tạo để chuyển các cập nhật trọng số theo độ dốc ngẫu nhiên giữa các công nhân. Có một số giải pháp để tránh phải thực hiện một số quy trình này.
Tensorflow phân tán có khả năng sử dụng máy chủ tham số để quản lý các công việc được phân phối. Điều này yêu cầu đặc điểm kỹ thuật của ClusterSpec, chứa địa chỉ IP / cổng của máy chủ nơi các tác vụ sẽ chạy. Các dự án như Kubeflow (thông qua tệp TFJob) hoặc Polyaxon có thể giúp thiết lập điều này, trên đầu cụm Kubernetes. Điều này vẫn yêu cầu mức độ tương tác với chính thiết lập cụm. Một số tập lệnh bổ sung được yêu cầu chẳng hạn để tự động hóa việc đóng gói.
Trong khi phương pháp được TensorFlow sử dụng thường là sử dụng máy chủ tham số để quản lý cập nhật trọng lượng trong một kịch bản đào tạo phân tán, thư viện Horovod của Uber đưa mọi thứ lên một cấp độ hiệu suất khác và dễ sử dụng. Nó sử dụng một cách khác để tính trung bình các độ dốc của trọng lượng giữa các công nhân. Thay vì tất cả các trọng số được tính trung bình thông qua một máy chủ tham số trung tâm, các nhân viên chỉ trao đổi một phần cập nhật gradient của họ với các nước láng giềng bằng cách sử dụng thuật toán ring-allreduce, giúp sử dụng băng thông mạng hiệu quả hơn nhiều. Nó sử dụng Giao diện truyền thông báo như Open MPI, cũng như sử dụng thư viện NCCL của NVIDIA để tối ưu hóa các quá trình truyền này cả trên một máy Đa GPU cũng như trên một cụm.
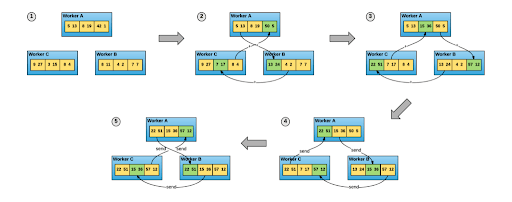
Horovod sử dụng thuật toán ring-allreduce để cho phép đào tạo phân tán hiệu quả mà không cần máy chủ tham số tập trung
Nguồn: https://eng.uber.com/horovod/
Về mặt dễ sử dụng, chỉ có một số lệnh để đưa vào mã đào tạo tiêu chuẩn để hỗ trợ đào tạo theo cách này – trình tối ưu hóa tiêu chuẩn được bao bọc trong một phiên bản phân phối tùy chỉnh. Ban đầu có hỗ trợ cho Tensorflow và Keras nhưng bây giờ các phiên PyTorch có thể được phân phối theo cách tương tự.
Horovod đã chứng tỏ mình trong việc cung cấp một công nghệ hỗ trợ hiệu quả và chúng tôi rất vui mừng khi thấy nó được hỗ trợ từ nhiều giải pháp vòng đời ML.
Vận dụng của chúng tôi
Tại Intuition Machines , chúng tôi không xa lạ với những thách thức của Học máy (ML) trên quy mô lớn. Chúng tôi đã trở thành chuyên gia trong việc cung cấp các giải pháp truy xuất dữ liệu và suy luận quy mô rất lớn, hiệu quả cho khách hàng của mình, tập trung vào Thị giác Máy tính, Hình ảnh và Video.
Đối với những tác vụ này, chúng tôi hiện khởi động Kubernetes của mình trong Azure và chúng tôi sử dụng kết hợp các nút GPU và nút ảo để mở rộng cụm phòng thí nghiệm của chúng tôi. Chúng tôi đang tích hợp Polyaxon, với tính năng đăng nhập một lần cơ bản để quản lý các thử nghiệm của mình, có thể dễ dàng truy cập vào cụm. Điều này cung cấp một cơ chế đơn giản để người dùng bắt đầu với sổ ghi chép Jupyter và nhanh chóng chuyển nó sang các công việc phân tán, quy mô lớn, hoàn thành với theo dõi thử nghiệm và tìm kiếm siêu tham số.
Về mặt dữ liệu, chúng tôi đã xem xét Pachyderm, đây là một Hadoop được xây dựng lại từ đầu và đi kèm với một số nhược điểm tương tự. Mặc dù Pachyderm tập trung vào “dữ liệu”, nó có các cơ chế riêng để xử lý dữ liệu này. Chúng tôi hiện đã có một đường ống tiền xử lý và chúng tôi cũng sử dụng OpenFaas và một hệ thống nội bộ gọi là Mongoose để xử lý tập dữ liệu lớn thường trú trên S3; tích hợp hệ thống xử lý của Pachyderm cho đến nay không mang lại lợi ích cho chúng tôi nhiều.
Tóm lược
Nhiều gói, thư viện và giải pháp trong số này đã xuất hiện trong năm ngoái và hầu hết vẫn đang ở giai đoạn Alpha hoặc Beta. Chúng tôi kỳ vọng sẽ thấy chúng phát triển nhanh chóng trong những tháng tới. Tuy nhiên, nhiều người đã ở trong tình trạng hữu ích để cải thiện quy trình làm việc trong thế giới thực mà nhiều đội ML đang gặp phải. Các tổ chức lớn hơn với các yêu cầu phức tạp hơn (đặc biệt là về mặt nhập dữ liệu) rất có thể sẽ được hưởng lợi nhiều nhất từ việc chọn từng phần riêng lẻ để tích hợp vào quy trình công việc ưa thích của họ hơn là áp dụng các giải pháp đi kèm theo đúng chủ đề và giai đoạn đầu như Kubeflow.
Nói rộng ra, chúng tôi thấy rằng một số giải pháp này được thiết kế với mục đích đào tạo dựa trên đám mây trong khi các giải pháp khác tập trung nhiều hơn vào việc làm cho quy trình làm việc ML end-to-end đơn giản hơn cho một hệ thống người dùng hoặc một nhóm nghiên cứu nhỏ. Chúng tôi đặc biệt vui mừng sử dụng các giải pháp dựa trên Kubernetes để có khả năng sử dụng năng động các tài nguyên đám mây và triển khai hiệu quả đào tạo phân tán trên quy mô lớn.
Tuy nhiên, các nhóm nhỏ hơn không có nhân tài DevOps nội bộ có thể được phục vụ tốt nhất bằng cách chọn một trong những giải pháp được lưu trữ đơn giản hơn như Azure Machine Learning Service hoặc Google Cloud ML Engine vào lúc này. Các cửa hàng lớn hơn với nhu cầu phức tạp hơn có khả năng nhận thấy rằng các hệ thống nguồn mở hoàn chỉnh có sẵn vẫn đang được hoàn thiện rất nhiều và do đó, việc chọn và chọn các thành phần tự gia tăng giá trị để cắm vào cơ sở hạ tầng nội bộ hiện có thường sẽ là con đường thiết thực nhất cho tương lai gần.
Nguồn MLconf
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI