
Sử dụng hệ thống đa GPU để Đào tạo Phân tán
Các nhà khoa học dữ liệu hoặc những chuyên gia Học máy đào tạo các mô hình AI trên quy mô lớn chắc chắn sẽ đạt đến giới hạn. Khi kích thước tập dữ liệu tăng lên, thời gian xử lý có thể tăng từ vài phút đến vài giờ, vài ngày đến vài tuần! Cần có giải pháp hiệu quả hơn để giải quyết vấn đề, đó là chuyển sang sử dụng hệ thống đa GPU cùng với đào tạo phân tán cho các mô hình học máy nhằm tăng tốc việc phát triển các mô hình AI hoàn chỉnh chỉ trong thời gian ngắn. Chúng tôi sẽ bàn về tính hữu ích của GPU so với CPU đối với việc học máy, tại sao đào tạo phân tán với nhiều GPU lại tối ưu cho các bộ dữ liệu lớn hơn và cách bắt đầu đào tạo các mô hình học máy bằng cách sử dụng các phương pháp thực hành tốt nhất.
→ Đào tạo phân tán với Máy trạm hỗ trợ nhiều GPU
Tại sao GPU lại tốt cho việc đào tạo các Neural Networks?
Giai đoạn đào tạo là phần sử dụng nhiều tài nguyên nhất của việc xây dựng mạng nơ-ron thần kinh (Neural Networks) hoặc mô hình học máy. Mạng nơ-ron yêu cầu đầu vào dữ liệu trong giai đoạn huấn luyện. Mô hình đưa ra một dự đoán có liên quan dựa trên dữ liệu đã xử lý trong các lớp dựa trên những thay đổi được thực hiện giữa các tập dữ liệu. Vòng dữ liệu đầu vào đầu tiên về cơ bản tạo thành đường cơ sở để mô hình học máy hiểu được; các bộ dữ liệu tiếp theo tính toán trọng lượng và thông số để đào tạo độ chính xác của phương pháp dự đoán bằng điện toán.

Đối với các bộ dữ liệu đơn giản hoặc số lượng ít, việc chờ đợi một vài phút là khả thi. Tuy nhiên, khi kích thước hoặc khối lượng dữ liệu đầu vào tăng lên, thời gian đào tạo có thể lên tới hàng giờ, hàng ngày hoặc thậm chí lâu hơn.
CPU phải vật lộn để xử lý trên một lượng lớn dữ liệu, chẳng hạn như các phép tính lặp lại trên hàng trăm nghìn dấu chấm động. Mạng nơ-ron sâu (Deep Neural Networks) bao gồm các phép toán như phép nhân ma trận và phép cộng vectơ.
Một cách để tăng tốc độ của quá trình này là chuyển đổi đào tạo phân tán với nhiều GPU. GPU cho đào tạo phân tán có thể đẩy quá trình đinh nhanh hơn CPU dựa trên số lượng lõi tensor được phân bổ cho giai đoạn đào tạo.
GPU hoặc Đơn vị xử lý đồ họa ban đầu được thiết kế để xử lý các phép tính lặp đi lặp lại trong việc ngoại suy và định vị hàng trăm nghìn hình tam giác cho đồ họa của các game đồ họa. Cùng với băng thông bộ nhớ lớn và khả năng bẩm sinh để thực hiện hàng triệu phép tính, GPU hoàn hảo để xử lý luồng dữ liệu tốc độ nhanh cần thiết cho đào tạo mạng nơ-ron qua hàng trăm vòng đào tạo, lý tưởng cho đào tạo học sâu.
Đào tạo phân tán trong học máy là gì?
Đào tạo phân tán lấy khối lượng công việc của giai đoạn đào tạo và phân phối nó đến nhiều bộ vi xử lý. Các bộ xử lý mini này hoạt động song song với nhau để tăng tốc quá trình đào tạo mà không làm giảm chất lượng của mô hình học máy. Khi dữ liệu được phân tách và phân tích song song, mỗi bộ xử lý nhỏ đào tạo một bản sao của mô hình học máy trên một lô dữ liệu đào tạo riêng biệt.
Kết quả được thông tin giữa các bộ xử lý (khi lô hoàn thành hoàn toàn hoặc khi mỗi bộ xử lý kết thúc lô của mình). Lần lặp lại tiếp theo bắt đầu lại với một mô hình mới đã được đào tạo một chút cho đến khi nó đạt được kết quả mong muốn.
Có hai cách phổ biến nhất để phân phối đào tạo giữa các bộ xử lý nhỏ (trong trường hợp của chúng tôi là GPU): song song dữ liệu và song song mô hình.
Song song dữ liệu – Data Parallelism
Data Parallelism là sự phân chia dữ liệu và phân bổ dữ liệu đó cho từng GPU để lượng giá bằng cách sử dụng cùng một mô hình AI. Khi tất cả các GPU hoàn tất quá trình chuyển tiếp, chúng sẽ xuất ra một ‘gradient’ hoặc các thông số đã học của mô hình. Vì có nhiều gradient chỉ có 1 mô hình AI để đào tạo, các gradient được biên dịch, tính trung bình và giảm xuống một giá trị duy nhất để cuối cùng cập nhật các thông số mô hình cho quá trình đào tạo của lần lặp tiếp theo. Điều này có thể được thực hiện đồng bộ hoặc không đồng bộ.
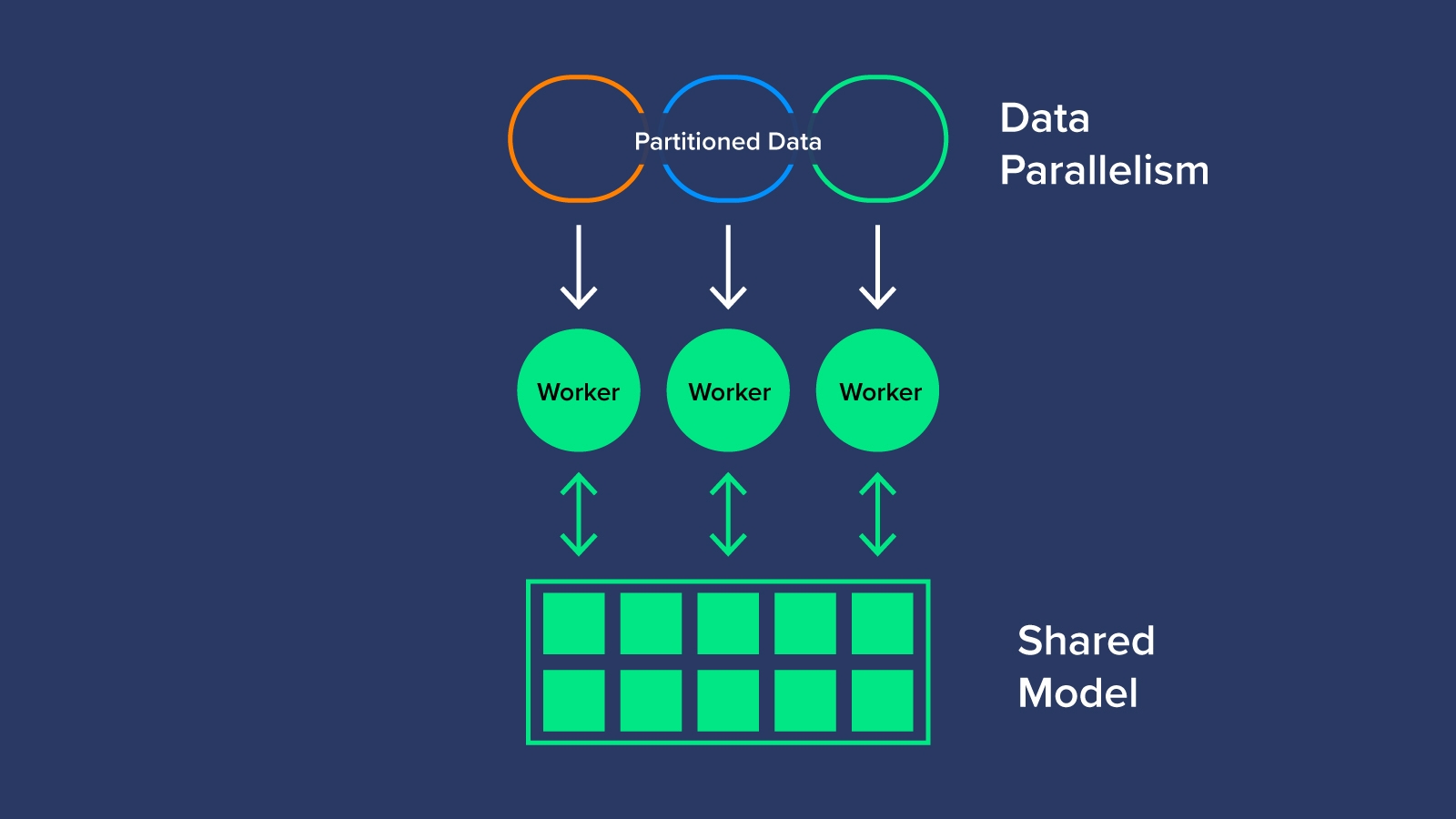
Synchronous Data Parallelism là nơi các nhóm GPU phải đợi cho đến khi tất cả các GPU khác hoàn thành việc tính toán các gradient, trước khi tính trung bình và giảm chúng để cập nhật các thông số cho mô hình. Khi các thông số đã được cập nhật thì mô hình có thể tiếp tục với lần lặp tiếp theo.
Asynchronous Data Parallelism là nơi GPU đào tạo độc lập mà không cần phải thực hiện tính toán gradient đồng bộ. Thay vào đó, các gradient được giao tiếp trở lại nơi tham số khi hoàn thành. Mỗi GPU không đợi GPU khác tính toán xong cũng như không tính toán trung bình gradient, do đó gọi là bất đồng bộ – asynchronous. Asynchronous Data Parallelism yêu cầu một máy chủ tham số riêng biệt cho phần học tập của mô hình, vì vậy sẽ tốn kém hơn một chút.
Việc tính toán gradient và tính trung bình dữ liệu đào tạo sau mỗi bước là công việc cần nhiều xử lý nhất. Vì chúng là các phép tính lặp đi lặp lại, nên GPU là sự lựa chọn để tăng tốc bước này nhằm đạt được kết quả nhanh hơn. Data Parallelism khá đơn giản và hiệu quả về mặt kinh tế, tuy nhiên, đôi khi mô hình quá lớn để phù hợp với một bộ xử lý nhỏ duy nhất.
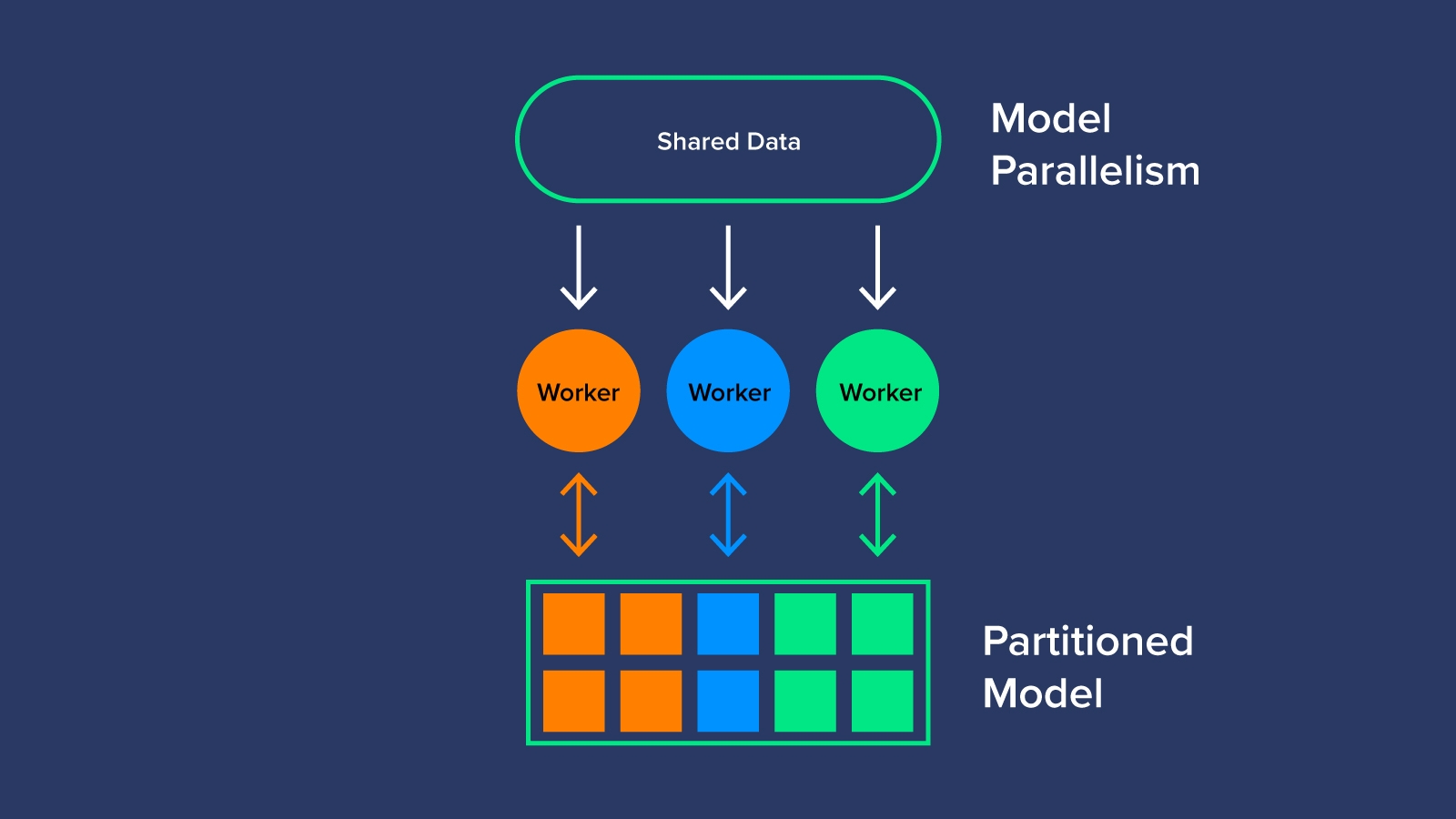
Song song Mô hình – Model Parallelism
Ngược lại với việc chia nhỏ dữ liệu, tính song song của mô hình sẽ chia mô hình (hoặc khối lượng công việc để đào tạo mô hình) trên các GPU worker. Việc phân đoạn mô hình sẽ chỉ định các nhiệm vụ cụ thể cho một hoặc nhiều worker để tối ưu hóa việc sử dụng GPU. Song song mô hình có thể được coi như một dây chuyền lắp ráp AI tạo ra một mạng nhiều lớp có thể hoạt động thông qua các tập dữ liệu lớn không khả thi đối với Data Parallelism. Mô hình song song cần một chuyên gia để xác định cách phân vùng mô hình nhưng dẫn đến việc khai thác và sử dụng hiệu quả hơn.
→ Nhất Tiến Chung cung cấp Máy chủ đa CPU và đa GPU chuyên cho AI và Học sâu. Tìm hiểu thêm tại đây.
Đào tạo phân tán đa GPU có nhanh hơn không?
Việc mua nhiều GPU có thể là một khoản đầu tư tốn kém nhưng đem lại tốc độ nhanh hơn nhiều so với các lựa chọn khác. CPU cũng đắt tiền và không thể mở rộng như GPU. Đào tạo các mô hình học máy của bạn trên nhiều lớp và nhiều GPU để đào tạo phân tán giúp tăng năng suất và hiệu quả trong giai đoạn đào tạo.
Tất nhiên, điều này có nghĩa là giảm thời gian dành cho việc đào tạo các mô hình của bạn, nhưng nó cũng mang lại cho bạn khả năng tạo ra (và tái tạo) kết quả nhanh hơn và giải quyết vấn đề trước khi bất kỳ điều gì vượt quá tầm tay. Về mặt tạo ra kết quả cho nỗ lực của bạn, đó là sự khác biệt giữa số tuần đào tạo so với số giờ hoặc số phút đào tạo (tùy thuộc vào số lượng GPU được sử dụng).
Vấn đề tiếp theo bạn cần giải quyết là làm thế nào để bắt đầu sử dụng nhiều GPU để đào tạo phân tán trong các mô hình học máy của bạn
Làm cách nào để đào tạo với nhiều GPU?
Nếu bạn muốn giải quyết vấn đề đào tạo phân tán với nhiều GPU, điều quan trọng đầu tiên là phải nhận ra liệu bạn sẽ cần sử dụng cơ chế Song song Dữ liệu hay Song song Mô hình. Quyết định này sẽ dựa trên kích thước và phạm vi của các tập dữ liệu của bạn.
Liệu bạn có thể cho mỗi GPU chạy toàn bộ mô hình với tập dữ liệu không? Hay sẽ tiết kiệm thời gian hơn khi chạy các phần khác nhau của mô hình trên nhiều GPU với bộ dữ liệu lớn hơn? Nói chung, Data Parallelism là tùy chọn tiêu chuẩn cho việc học phân tán. Bắt đầu với Song song Dữ liệu đồng bộ trước khi nghiên cứu sâu hơn về Song song Mô hình hoặc Song song Dữ liệu bất đồng bộ trong đó cần một máy chủ tham số chuyên dụng riêng biệt.
Chúng ta có thể bắt đầu liên kết các GPU của bạn với nhau trong quá trình đào tạo phân tán của bạn.
- Chia nhỏ dữ liệu của bạn dựa trên quyết định phân bổ song song của bạn. Ví dụ: bạn có thể sử dụng lô dữ liệu hiện tại (lô toàn cầu) và chia nó thành tám lô con (lô cục bộ). Nếu lô toàn cầu có 512 mẫu và bạn có tám GPU, thì mỗi trong tám lô cục bộ sẽ bao gồm 64 mẫu.
- Mỗi GPU trong số tám GPU, hoặc bộ xử lý nhỏ, chạy một lô cục bộ một cách độc lập: chuyển tiếp, chuyển ngược, xuất gradient của trọng số, v.v.
- Các sửa đổi trọng lượng từ độ dốc cục bộ được kết hợp hiệu quả trên tất cả tám bộ xử lý nhỏ để mọi thứ luôn đồng bộ và mô hình đã được đào tạo phù hợp (khi sử dụng song song dữ liệu đồng bộ).
Điều quan trọng cần nhớ là một GPU cho đào tạo phân tán sẽ cần lưu trữ dữ liệu đã thu thập và kết quả của các GPU khác trong giai đoạn đào tạo. Bạn có thể gặp phải vấn đề một GPU hết bộ nhớ nếu không chú ý kỹ.
Ngoài ra, lợi ích vượt xa chi phí khi xem xét đào tạo phân tán với nhiều GPU! Cuối cùng, mỗi GPU giảm thời gian dành cho giai đoạn đào tạo, tăng hiệu quả mô hình và tạo ra kết quả cao hơn khi bạn chọn Song song Dữ liệu chính xác cho mô hình của mình.
Tìm kiếm thêm thông tin về đào tạo phân tán và các chủ đề học máy khác?
Mạng nơ-ron là phần công nghệ rất phức tạp và chỉ riêng giai đoạn đào tạo đã có thể gặp nhiều khó khăn. Bằng cách tận dụng và tìm hiểu thêm về cách bạn có thể tận dụng phần cứng bổ sung để tạo ra các mô hình hiệu quả hơn trong thời gian ngắn hơn, khoa học dữ liệu có thể thay đổi thế giới của chúng ta! GPU dành cho đào tạo phân tán rất xứng đáng với khoản đầu tư ban đầu khi bạn có thể tạo ra các mạng thần kinh hiệu quả hơn trong vài tuần và vài tháng thay vì vài tháng và vài năm.
Chúng tôi khuyến khích bạn bắt đầu đào tạo phân tán và học sâu. Xem thêm các bài viết khác liên quan đến chủ đề học máy trên blog của chúng tôi.
Bài viết liên quan
- Tôi có cần CPU kép không?
- HPE với các giải pháp phát triển mô hình Trí tuệ nhân tạo
- Các công cụ và framework AI mới nhất: Phân tích so sánh
- Scikit-learn một thư viện quan trọng cho ML trên ngôn ngữ lập trình Python
- Các ứng dụng của Generative AI trong Học sâu, Khoa học đời sống và Sáng tạo nội dung
- Dask – Một thư viện mã nguồn mở cho tính toán song song với Python