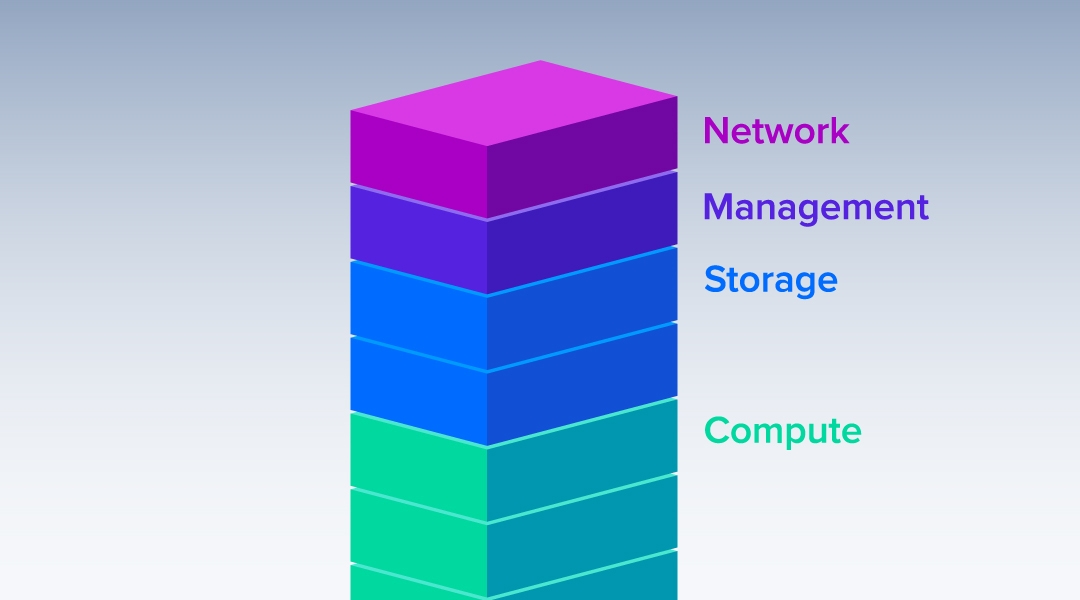
Cụm máy chủ – Server Cluster là gì?
Đầu tiên cần định nghĩa rõ thế nào là một cluster: Một cách đơn giản, cluster KHÔNG phải là một máy tính duy nhất có nhiều GPU hoặc nhiều socket CPU.
Phân loại chung của một máy chủ / hệ thống đơn như vậy sẽ được coi là một node xử lý (compute node), cụ thể hơn là node xử lý được tăng tốc bởi GPU mà sẽ được bàn chi tiết ở phần sau.
Vậy, một cluster là gì? Một cluster về cơ bản là một tập hợp các hệ thống máy chủ được kết nối với nhau để cung cấp giải pháp “chìa khóa trao tay”, được tối ưu để cho phép xử lý song song các công việc tính toán như đào tạo học sâu (Deep Learning Training), mô phỏng động lực học phân tử AMBER hoặc thậm chí một số phần mềm tính toán CPU cũ hơn như LAMMPS được sử dụng trong siêu máy tính và phòng thí nghiệm lớn. Tuy nhiên, chúng ta có thể chia cluster thành năm thành phần:

1) Rack
2) Management Node
3) Compute Node
4) Storage
5) Network Switch
Rack
Rack (viết đầy đủ là rack enclosure) là kệ tủ chuyên dụng để chứa các máy chủ rackmount, thiết bị chuyển mạch, PDU và hệ thống cáp mạng được tổ chức bên trong. Rack có thể có kích thước bằng một nửa như 24U, đến 48U (chữ “U” hoặc thường được gọi là “RU” là đơn vị đo lường để xác định “chiều cao” của máy chủ).

Thế Giới Máy Chủ khuyến nghị các khách hàng ưu tiên dùng tủ rack 42U, vì cho phép mở rộng quy mô các hệ thống bổ sung trong tương lai sẽ được thêm vào cluster.

Management Node
Một node quản lý, thường được gọi là login node, hoặc head node, là bộ điều phối chính của cụm. Đây là hệ thống có tính sẵn sàng cao nhất, cung cấp một hệ thống duy nhất để đăng nhập vào, để các quản trị viên hệ thống, các chuyên viên nghiên cứu có thể đăng nhập, chạy và hoặc lên lịch công việc cho dự án của họ.
Một điều tuyệt vời về cách các chức năng của node quản lý dựa trên phần mềm quản lý cluster được cài đặt như Bright Cluster Management hay Microsoft Cluster Server,… Bright giúp theo dõi các nút, cho phép vận hành / snapshot các nút mới được thêm vào và trên hết, về cơ bản, liên kết tất cả các hệ thống với nhau.
Một kịch bản quản lý node điển hình:
Giả sử một node cấp dưới (compute node) được bật lên trong cụm. Node cấp dưới này sẽ khởi động thông qua PXE boot trong management network đến node quản lý và node quản lý sẽ nhận ra, thông qua địa chỉ MAC, vai trò tương ứng của compute node. Node quản lý sẽ triển khai hoặc “chụp ảnh” boot image đã được lưu tương ứng trở lại node cấp dưới; sau đó node phụ sẽ khởi động, thiết lập phần mềm và mạng cho mỗi boot image cụ thể, và sẵn sàng chấp nhận các job đi đến để chạy trên node.
Các node xử lý – Compute Node
Các nút xử lý là hệ thống “công nhân”, về bản chất, là các hệ thống thực hiện công việc xử lý nặng nhọc nhất.
Chúng có thể được chia thành hai loại chính:
1) Các node CPU, và;
2) Các node được GPU tăng tốc.
Các node CPU thường sử dụng một lượng lớn CPU core như CPU AMD EPYC, lõi xử lý có tần số cao (nhanh) hoặc kết hợp cả hai.
Các node GPU có thể được trang bị GPU, FPGA hoặc các bộ tăng tốc xử lý song song khác và dựa vào sức mạnh và bộ nhớ xử lý song song khổng lồ của các thiết bị cấp doanh nghiệp này.
Nhiều trung tâm nghiên cứu trang bị một tủ rack chứa cả các node xử lý CPU và GPU, nơi tổng số cluster có thể linh hoạt và phù hợp với các tình huống sử dụng cụ thể. Bằng cách này, cluster có thể linh hoạt và phục vụ nhiều người dùng và nhiều ứng dụng yêu cầu nhiều loại phần cứng hơn. Ví dụ: các ứng dụng tăng tốc CPU có thể có các node CPU hiệu suất cao để chạy, trong khi các ứng dụng tăng tốc bằng GPU có các node GPU để chạy.
Storage
Như tên của nó, storage là nhóm lưu trữ được chia sẻ chung có thể chứa dữ liệu kết quả, hình ảnh, code hoặc bất kỳ thứ gì khác cụ thể cho một dự án nghiên cứu. Storage có thể đơn giản là NAS (Networked Attached Storage) hoặc các thành phần lưu trữ song song tốc độ cao, phức tạp hơn như các giải pháp DDN, Panasas hoặc thậm chí là một parallel strorage cluster chuyên dụng.
Mỗi thành phần này có thể được giải thích và mổ xẻ sâu hơn trong các thiết lập của chúng. Thông thường, Thế Giới Máy Chủ đề xuất một kho lưu trữ / mount chia sẻ duy nhất có thể được kết hợp trong node quản lý và thường là cách triển khai đơn giản nhất để đảm bảo không gian lưu trữ được chia sẻ từ trung tâm.
Network
Kết nối mạng trong một cluster thường có hai dạng:
1) Management network, và;
2) Internal network và tùy chọn mạng HS-network (tốc độ cao) (10/25/40/100 / 200GBE, IB, v.v.).
Mạng management và hạ tầng nói chung là mạng Gigabit giá rẻ và không tốn kém được sử dụng trong phần mềm quản lý cluster để cho phép hệ thống khởi động, cung cấp và quản lý nội bộ (IPMI) của tất cả các node quản lý và các node xử lý.
Mạng nội bộ nói chung là mạng kết nối giữa node quản lý với các node xử lý và là mạng chính để dữ liệu được truyền giữa các node xử lý và node quản lý trong quá trình chạy các tác vụ. Thông thường, nó có thể là 10GBase-T (hoặc tối thiểu 1GbE cho các cụm AMBER) cho kết nối bình thường và kết nối tốc độ cao như 100GbE hoặc InfiniBand. Với mạng tốc độ cao này, mạng này thường có ngõ vào (hoặc uplink) từ mạng bên ngoài để các nhóm nghiên cứu và chuyên viên đăng nhập từ xa vào cụm để chạy hoặc lên lịch công việc của họ.
Nhìn chung, các cụm có khả năng tùy biến cao và thường được điều chỉnh cho phù hợp với các nhóm hoặc tổ chức nghiên cứu.
Vui lòng liên hệ với Thế Giới Máy Chủ ngay hôm nay để tìm hiểu cách các chuyên viên của chúng tôi có thể tối ưu hóa và tạo ra giải pháp cluster tốt nhất cho dự án AI, Deep Learning của bạn.
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI