
Công nghệ ảo hóa đang được áp dụng rộng rãi nhờ sự linh hoạt, nhanh chóng, ổn định và dễ quản trị mà nó đem lại. Đồng thời, bất kỳ công nghệ IT nào – phần cứng hoặc phần mềm – đều chỉ có thể hoạt động tốt theo chế độ bảo trì đầy đủ, và nền tảng VMware cũng thế. Với các máy chủ vật lý, lỗi hoặc hiệu suất hoạt động kém của hệ thống ảnh hưởng đến các ứng dụng chạy trên nó. Với nền tảng ảo hóa, nhiều máy ảo (VM) chạy trên cùng một máy chủ vật lý và sự chậm chạp của máy chủ sẽ ảnh hưởng đến các ứng dụng chạy trên tất cả các VM. Do đó, việc giám sát hiệu suất thậm chí còn quan trọng hơn bên trong cơ sở hạ tầng ảo hóa so với các loại hạ tầng vật lý.

| Hiệu năng của các ứng dụng chạy trên máy ảo phụ thuộc vào nhiều yếu tố: |
|---|
|
Phân bổ quá mức (over-allocate) tài nguyên cho VM cũng không phải là giải pháp tốt. Thứ nhất, phân bổ quá mức dẫn đến việc sử dụng kém phần cứng bên dưới, do đó mang lại lợi tức đầu tư kém. Thứ hai, việc phân bổ quá nhiều CPU cho máy ảo có thể khiến nó bị đình trệ chờ đợi đủ tài nguyên CPU có sẵn, do đó ảnh hưởng đến hiệu suất.
Vậy, làm thế nào để xác định đâu là lượng tài nguyên phù hợp để phân bổ cho VM? Câu trả lời cho câu hỏi đó nằm ở việc theo dõi việc sử dụng tài nguyên của máy ảo theo thời gian, xác định định mức sử dụng và sau đó sizing hợp lý cho VM.

Nhưng làm thế nào để theo dõi các số liệu sử dụng tài nguyên cho VM và cái nào là quan trọng? VMware vSphere bao gồm nhiều thành phần tài nguyên khác nhau. Biết các thành phần này là gì và mỗi thành phần ảnh hưởng đến các quyết định quản lý tài nguyên là chìa khóa để quản lý VM hiệu quả. Trong bài này, chúng tôi sẽ thảo luận về 10 thông số hàng đầu mà mọi quản trị viên VMware phải liên tục theo dõi.
Top 10 chỉ số hiệu năng cho quản trị viên VMware |
|---|
|
#1 Memory Ballooning
Memory Ballooning (thổi phồng bộ nhớ) là một kỹ thuật phục hồi bộ nhớ được sử dụng bởi hypervisor để cho phép hệ thống máy chủ vật lý lấy lại bộ nhớ không được sử dụng từ các VM, nghĩa là các VM đang bị thiếu bộ nhớ có thể sử dụng bộ nhớ được thu hồi (re-claimed).
Thông thường, hypervisor sẽ cấp phát một phần bộ nhớ máy chủ vật lý cho mỗi VM. Hệ điều hành guest chạy bên trong mỗi VM không nắm được tổng bộ nhớ có sẵn cho cả máy chủ vật lý. Memory Ballooning làm cho hệ điều hành guest nhận biết sự thiếu hụt bộ nhớ của máy chủ vật lý. Bất cứ khi nào máy chủ vật lý phải đối mặt với sự tranh giành bộ nhớ, trình điều khiển Ballooning được cài đặt trong hệ điều hành guest sẽ xác định xem bộ nhớ không sử dụng có thể được lấy lại từ bất kỳ VM nào không. Sau đó, trình điều khiển sẽ xác định lượng tài nguyên bộ nhớ trên VM đang sử dụng dư thừa bộ nhớ đã cấp phát, và sau đó ra hiệu cho hypevisor lấy lại bộ nhớ chưa sử dụng này từ VM đó. Kế đến, hypervisor sẽ cung cấp bộ nhớ dư thừa này cho bất kỳ VM nào bị thiếu bộ nhớ trên máy chủ.
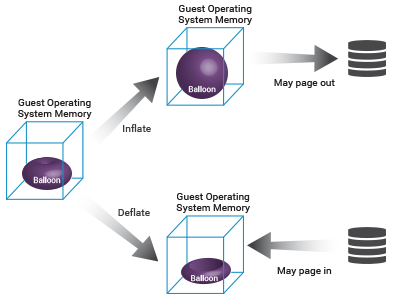
Ballooning cho phép sử dụng hiệu quả bộ nhớ vật lý nhưng phải đánh đổi với việc hiệu năng VM giảm đi đôi chút. Điều này là do quá trình thực hiện Memory Ballooning quá mức trên hypervisor có thể khiến hệ điều hành guest phải đọc từ ổ cứng. Disk I/O cao có thể làm giảm hiệu suất VM. Để ngăn chặn tình trạng Memory Ballooning quá mức, các quản trị viên phải liên tục theo dõi lượng bộ nhớ mà hypervisor đang lấy lại từ các VM và đảm bảo rằng nó không phát triển quá gần với mục tiêu Ballooning đã được đặt. Việc giám sát VM và hệ điều hành guest đơn thuần sẽ ít hữu ích trong vấn đề này. Người ta phải theo dõi hoạt động Ballooning ở cấp độ hypervisor để chủ động phát hiện và kiểm soát sự dư thừa.
#2 Memory Swapping
Memory Swapping (hoán đổi bộ nhớ) xảy ra khi trạng thái bộ nhớ của máy chủ VMware vSphere là ‘hard’ hoặc ‘low’. Bộ nhớ vSphere chuyển sang một trong những trạng thái này khi các kỹ thuật thu hồi như ballooning, page sharing và compression không thể theo kịp tốc độ cấp phát bộ nhớ của VM. Tại thời điểm này, vSphere sẽ cần đến hoạt động Memory Swapping.
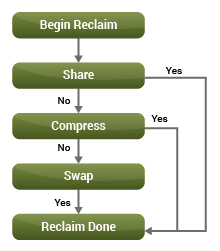
Swapping xảy ra ở hệ điều hành guest và cấp độ hypevisor.
- Với hypervisor-level swapping, memory page trên VM được hoán đổi qua khu vực swapping trên hypervisor. Mỗi VM được liên kết với không gian trao đổi riêng của nó. Khi hệ điều hành khách truy cập một memory page từ không gian hoán đổi, vSphere sẽ xử lý quyền truy cập bằng cách hoán đổi trong page đó từ không gian hoán đổi. Việc chờ đợi vCPU có thể tăng trong các hoạt động trao đổi, gây ra tác động tiêu cực đến hiệu suất VM. Hơn nữa, không gian hoán đổi không đủ cũng có thể làm giảm hiệu suất VM.
- Trong trao đổi cấp hệ điều hành khách, mỗi khi CPU truy cập trang bộ nhớ ảo trên hệ điều hành khách, trang bộ nhớ đó được hoán đổi vào bộ nhớ vật lý. Bằng cách này, các trang bộ nhớ ảo thường được truy cập trở nên có sẵn trong bộ nhớ vật lý, để chúng có thể được phục vụ nhanh chóng. Các trang bộ nhớ hiếm khi được sử dụng được hoán đổi để lưu trữ. Do đó, với việc hoán đổi, có nguy cơ I / O đĩa cao và tính toán chậm, do việc đọc và ghi thường xuyên và tỷ lệ hoán đổi cao giữa bộ nhớ vật lý và lưu trữ.
Các giải pháp giám sát chỉ tập trung vào hiệu suất VM sẽ có thể thu được VM chậm; nhưng sẽ không thể chẩn đoán nguyên nhân gốc rễ của nó. Một giải pháp giám sát VMware lý tưởng là một giải pháp có thể theo dõi tỷ lệ trao đổi và trao đổi ở cấp độ hypervisor và ở cấp độ hệ điều hành khách, tự động tương quan các số liệu này và xác định chính xác hiệu suất của VM là gì. Nó cũng rất quan trọng để theo dõi cấu hình bộ nhớ và dự phòng trên mỗi VM, vì điều đó sẽ mang lại cho các quản trị viên cảm giác hợp lý về việc có bao nhiêu không gian hoán đổi khi xử lý VM.
#3 VM CPU Wait and VM CPU Ready
CPU ảo của VM (vCPU) có thể ở một trong bốn trạng thái cơ bản: run, wait, co-stop và ready.
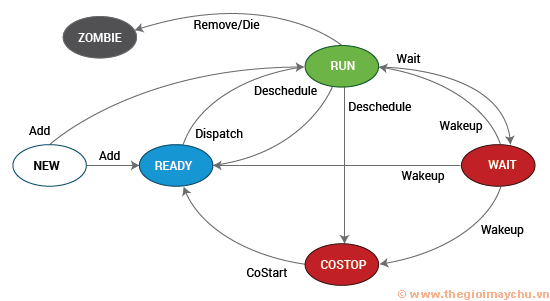
Từ quan điểm giám sát hiệu suất, điều bắt buộc là các quản trị viên phải biết khi nào và trong bao lâu VM đã ở trong trạng thái chờ đợi và sẵn sàng của vCPU.
vCPU Wait Time
Một VM đang chờ một nhiệm vụ hoàn thành có thể không yêu cầu vCPU của nó ngay lập tức. Thời gian mà VM giữ vCPU chờ cho mục đích này là thời gian chờ vCPU. Thông thường, một VM có thể đợi vì nó không có gì để làm cho đến khi một sự kiện xảy ra. Ví dụ, hết hạn gói mạng hoặc bộ đếm thời gian. Điều này được gọi là chờ đợi nhàn rỗi. Cao và thấp trong thời gian chờ nhàn rỗi là không đáng kể vì chúng không ngụ ý một điều kiện vấn đề. Mặt khác, nếu VM đang chờ đọc / ghi trên bộ lưu trữ để hoàn thành và không thể làm gì khác cho đến khi hoàn thành, nó được gọi là chờ I / O. Không giống như chờ đợi nhàn rỗi, chờ đợi I / O có tác động hiệu suất. Thời gian chờ I / O lâu hơn, hoạt động VM sẽ chậm hơn. Chờ đợi I / O cũng là dấu hiệu của việc lưu trữ không có sẵn, quá tải hoặc tiềm ẩn. Do đó, điều quan trọng là các quản trị viên phải theo dõi thời gian chờ đợi I / O của vCPU trên mỗi VM.
vCPU Ready Time
Thời gian sẵn sàng của vCPU là phần trăm thời gian VM đã sẵn sàng nhưng không thể chạy CPU vật lý. Một trong những nguyên nhân phổ biến cho thời gian sẵn sàng vCPU cao là đăng ký quá nhiều. Nếu VM được phân bổ nhiều vCPU hơn CPU vật lý (pCPU) có sẵn trên máy chủ, thì trong thời gian tải nặng, khi lý tưởng, tất cả các vCPU phải chạy toàn thời gian, nhiều vCPU có thể không chạy vì muốn có pCPU. Kết quả: VM và các ứng dụng chạy trên nó sẽ thiếu sức mạnh xử lý, do đó, sẽ làm giảm hiệu suất của VM. Do đó, điều quan trọng là phải theo dõi thời gian sẵn sàng vCPU của mỗi VM. Nếu số liệu này là hơn 5% cho một VM, nó chỉ ra rằng VM chậm. Bạn có thể tương quan số liệu này với việc sử dụng CPU của máy chủ lưu trữ để tìm hiểu xem liệu có sự tranh chấp về tài nguyên CPU vật lý trong cùng thời gian vCPU sẵn sàng tăng vọt không. Nếu vậy, bạn có thể kết luận rằng VM đang đăng ký quá mức vào tài nguyên CPU của máy chủ lưu trữ. Để ăn mòn, bạn cũng có thể theo dõi số lượng pCPU có sẵn cho máy chủ và số lượng vCPU được phân bổ cho mỗi VM. Điều này sẽ chỉ cho bạn các VM quá khổ và nhắc bạn thay đổi kích thước các VM đó, để có thể giảm thiểu thời gian sẵn sàng của vCPU. Tỷ lệ vCPU và pCPU được đề xuất là từ 1:1 đến 3:1.
#4 Large and Old VM Snapshots
Ảnh chụp nhanh ghi lại toàn bộ trạng thái của máy ảo tại thời điểm ảnh chụp được thực hiện. Nó bao gồm các nội dung của bộ nhớ ảo Bộ nhớ ảo, cài đặt máy ảo và trạng thái của tất cả các đĩa ảo của máy ảo.
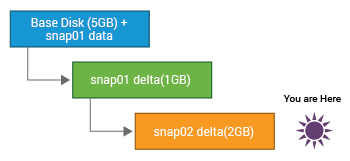
Sau khi một ảnh chụp nhanh được thực hiện, mọi thay đổi cần được thực hiện đối với đĩa ảo gốc (VMDK) trước tiên được ghi vào một tệp ảnh chụp nhanh đang phát triển. Tùy thuộc vào mức độ hoạt động trên VM, theo thời gian, tệp ảnh chụp nhanh này thậm chí có thể phát triển theo kích thước của tệp đĩa ảo gốc. Khi có nhiều tệp ảnh chụp nhanh, việc sử dụng không gian đĩa kết hợp của chúng thậm chí có thể vượt quá kích thước của tệp đĩa ảo gốc. Nếu không đủ dung lượng đĩa cho VM, thì các snapshot lớn có thể khiến vị trí lưu trữ snapshot hết dung lượng, do đó ảnh hưởng xấu đến hiệu suất VM. Điều tồi tệ hơn là một hoặc nhiều máy ảo siêu hoạt động sử dụng cùng một kho dữ liệu thậm chí có thể sinh ra các tệp ảnh chụp nhanh phát triển để tiêu thụ toàn bộ không gian kho dữ liệu! Điều này có thể ảnh hưởng nghiêm trọng đến hiệu suất của tất cả các máy ảo khác khi sử dụng kho dữ liệu đó. Do đó, quản trị viên nên để mắt đến các tệp ảnh chụp nhanh lớn bất thường, kiểm tra nội dung của chúng để xem các thay đổi mà chúng giữ đã được cam kết với đĩa chưa và xóa tệp ảnh chụp nhanh mà không có bất kỳ thay đổi nào không được cam kết, vì tệp đó không còn nữa hữu ích. Điều này sẽ giúp tiết kiệm không gian lưu trữ và đảm bảo hiệu suất cao nhất của máy ảo.

#5 Idle/Orphaned VMs
Máy ảo zombie / zombie là những máy ảo vẫn đang chạy và tiếp tục tiêu thụ CPU, bộ nhớ và tài nguyên lưu trữ có giá trị, mặc dù chúng không còn được sử dụng. Ví dụ: giả sử, một máy ảo được gán cho một nhân viên, người sau đó sẽ từ chức. Nhưng nếu VM đó không ngừng hoạt động cũng như không được gán cho người dùng khác sau đó, VM đó sẽ trở thành một VM nhàn rỗi.
VM mồ côi là những VM tồn tại dưới dạng dữ liệu trong cơ sở dữ liệu máy chủ vCenter nhưng đã bị xóa hoặc không còn được đăng ký với máy chủ. Đôi khi, một đĩa VMDK hoặc các tệp riêng lẻ có thể bị mồ côi. Một số nguyên nhân phổ biến cho kịch bản không mong muốn này là:
- Một chuyển đổi dự phòng máy chủ hoặc di chuyển DRS không thành công.
- Loại bỏ VM khỏi kho lưu trữ khi được kết nối trực tiếp với vSphere thay vì vCenter.
- Khôi phục máy chủ vCenter hoặc cơ sở dữ liệu của nó từ bản sao lưu hoặc ảnh chụp nhanh.
Cả máy ảo nhàn rỗi và máy ảo mồ côi đều làm cạn kiệt tài nguyên vật lý một cách không cần thiết, khiến hiệu suất của máy ảo hoạt động bị ảnh hưởng. Hơn nữa, sự phổ biến của các VM như vậy dẫn đến ảo hóa hoặc mở rộng VM – một điều kiện trong đó số lượng VM đạt đến tỷ lệ không thể quản lý được. Theo dõi số lượng và trạng thái của máy ảo trên máy chủ sẽ giúp quản trị viên cách ly và lấy lại các tài nguyên không sử dụng và cho phép chúng quản lý hiệu quả hoạt động của VM.
#6 VM Disk Read/Write IOPS and Throughput
Các chỉ số phổ biến nhưng chính xác nhất về sức khỏe của đĩa ảo là thông lượng đĩa và IOPS của đĩa. Mức thông lượng mà một đĩa ảo có thể cung cấp và số lượng các hoạt động đọc / ghi mà nó có thể hỗ trợ trong một giây xác định mức độ nhanh chóng mà đĩa ảo có thể xử lý các lệnh hoặc yêu cầu I / O. Nếu một đĩa ảo không có kích thước với công suất xử lý thông lượng hoặc I / O đầy đủ, VM sử dụng đĩa ảo đó và các ứng dụng hoạt động trên VM đó sẽ bị chậm đi đáng kể. Hơn nữa, nếu VM / ứng dụng gửi nhiều thông lượng hơn so với đĩa ảo của nó được cấu hình để hỗ trợ, nó sẽ tăng áp lực lên vCPU và bộ nhớ ảo của VM đó. Điều này đến lượt nó có thể khiến VM hút thêm CPU và bộ nhớ vật lý, do đó khiến các VM khác tranh giành tài nguyên vật lý hạn chế. Điều này cũng có thể dẫn đến sự suy giảm hiệu năng của các máy ảo khác. Để tránh các nghịch cảnh như vậy, quản trị viên nên theo dõi chặt chẽ thông lượng và IOPS trên mỗi đĩa ảo, tương quan thời gian với các giá trị này với việc sử dụng CPU và bộ nhớ và chủ động xác định xem có phải thay đổi kích thước bộ nhớ không.
#7 Datastore Capacity Usage and Availability
VMware vSphere sử dụng kho dữ liệu để lưu trữ tất cả các tệp được liên kết với các máy ảo của nó. Kho dữ liệu là một đơn vị lưu trữ logic có thể sử dụng không gian đĩa trên một thiết bị vật lý, một phân vùng đĩa hoặc trải rộng trên một số thiết bị vật lý.
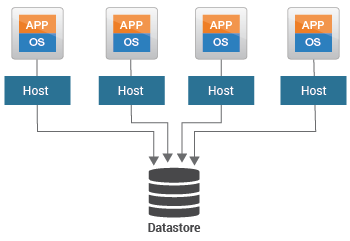
Không có kho dữ liệu, VMware vSphere không thể cung cấp VM. Nếu kho dữ liệu trở nên không khả dụng đột ngột, thì người dùng sẽ bị từ chối truy cập vào tất cả các máy ảo / ứng dụng sử dụng kho dữ liệu đó. Để đảm bảo người dùng truy cập không bị gián đoạn vào máy ảo / ứng dụng của họ, quản trị viên nên giữ các tab về trạng thái kho dữ liệu, phát hiện kịp thời sự không có sẵn của nó, nhanh chóng cách ly nguyên nhân gốc của nó và khắc phục nó.
Việc sử dụng quá mức không gian đĩa trong kho dữ liệu cũng có thể dẫn đến suy giảm đáng kể hiệu năng VM. Nếu hơn 75% không gian đĩa của kho dữ liệu được sử dụng, nó báo hiệu một tiềm năng ‘chiến đấu vì không gian trong số các máy ảo chia sẻ kho dữ liệu đó. Trong các tình huống như vậy, quản trị viên nên nhanh chóng xác định VM đang đói không gian và hiểu lý do tại sao nó tiêu tốn không gian một cách ích kỷ. Nếu không, điều này có thể khiến các máy ảo khác sử dụng cùng kho dữ liệu bị ảnh hưởng nghiêm trọng về hiệu năng.
Các vấn đề liên quan đến tính khả dụng của kho dữ liệu và việc sử dụng không gian trở nên rõ rệt hơn khi kho dữ liệu được cấu hình trên bộ lưu trữ ngoài như SAN / NAS. Lý do là, trong trường hợp này, cấu hình sai hoặc trở ngại trong các hoạt động nội bộ hoặc mất liên lạc với thiết bị lưu trữ bên ngoài bên dưới cũng có thể ảnh hưởng đến sức khỏe kho dữ liệu. Do đó, quản trị viên có thể giám sát các mảng lưu trữ riêng lẻ cùng với VM và kho dữ liệu, tương quan thông minh các vấn đề trên các tầng lưu trữ và ảo hóa và cách ly chính xác vị trí tắc nghẽn.
#8 VM Network Connectivity
Khi người dùng phàn nàn rằng VM không thể truy cập hoặc chậm, lý do có thể không phải luôn luôn là do VM đã bị tắt nguồn hoặc đang gặp phải sự tranh chấp tài nguyên nội bộ. Thông thường, các vấn đề như vậy có thể được quy cho sự gián đoạn tạm thời / kéo dài trong kết nối mạng hoặc kết nối mạng tiềm ẩn với VM. Do đó, việc theo dõi sức khỏe bên trong của VM sẽ không đủ. Điều quan trọng nữa là các quản trị viên phải theo dõi kết nối với từng VM từ góc độ bên ngoài. Viễn cảnh này hữu ích hơn khi người dùng đến môi trường ảo hóa của bạn đến từ các vùng địa lý khác nhau! Giám sát kết nối bên ngoài trong các môi trường như vậy sẽ hướng quản trị viên đến các khu vực địa lý cụ thể phải đối mặt với các vấn đề kết nối liên tục. Theo dõi trạng thái và hiệu suất của các công tắc ảo và cổng ảo cũng giúp khắc phục sự cố kết nối hiệu quả.
#9 Hardware Health
Thất bại của phần cứng gây ra một đòn chí mạng cho sức khỏe của máy chủ vSphere và VM. Bộ xử lý ngừng hoạt động, quạt đã ngừng hoạt động, đột ngột và tăng đột biến về nhiệt độ / điện áp của phần cứng, phân vùng bộ nhớ bị hỏng, v.v., có thể làm tổn thương ngay lập tức một máy chủ vật lý, làm giảm cả máy chủ và máy ảo trên đó. Do đó phát hiện kịp thời và phục hồi nhanh chóng từ các lỗi phần cứng là rất quan trọng.
Giống như phần cứng máy chủ, trạng thái phần cứng VM cũng cần được theo dõi, vì các lỗi phần cứng mà VM gặp phải có thể ảnh hưởng xấu đến hiệu suất và hiệu suất của VM.
#10 VM Resource Usage (Inside and Outside View)
Giám sát việc sử dụng tài nguyên của máy ảo từ máy ảo hóa, tức là, từ ‘bên ngoài máy ảo – sẽ chỉ cho bạn các máy ảo bị thiếu tài nguyên trên máy chủ. Tuy nhiên, để biết lý do tại sao VM tiêu thụ tài nguyên quá mức, điều quan trọng là các quản trị viên phải đo hiệu suất của VM từ bên trong VM, tức là, theo dõi cách VM sử dụng tài nguyên CPU, bộ nhớ, mạng và ổ đĩa được phân bổ cho nó. Điều này sẽ hướng quản trị viên đến nguyên nhân gốc rễ của sự tranh chấp tài nguyên ở cấp VM.
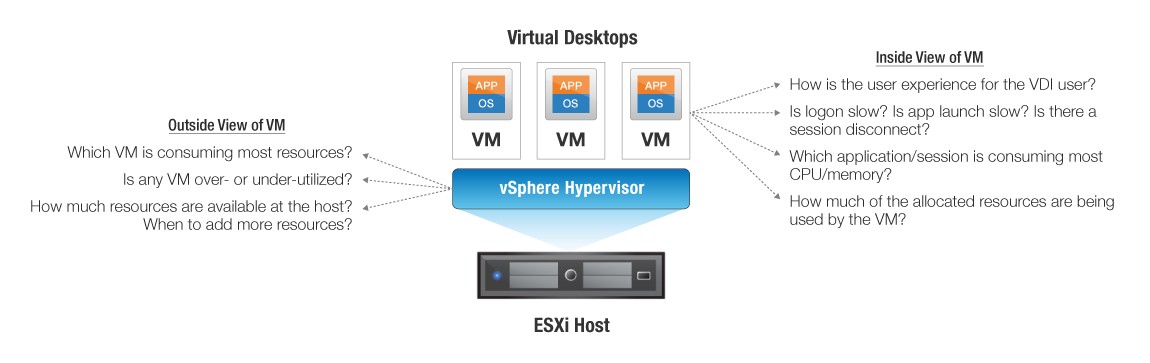
Cách tiếp cận phổ biến nhất để giám sát việc sử dụng tài nguyên VM là cài đặt màn hình / tác nhân trên mỗi VM. Cách tiếp cận này không được khuyến khích vì nó tốn thời gian và leo thang chi phí. Lý tưởng nhất, một giải pháp giám sát sẽ có thể cung cấp những hiểu biết sâu sắc về các hoạt động nội bộ và sử dụng tài nguyên của từng VM mà không yêu cầu một màn hình / tác nhân trên mỗi VM.
Các số liệu này chỉ là phần nổi của tảng băng giám sát VMware! Để có hiệu suất VM tốt nhất, quản trị viên cũng có thể muốn theo dõi trạng thái và phiên bản của Công cụ VMware được cài đặt trên mỗi VM. Việc sử dụng GPU và vGPU cũng cần được giám sát để cả máy chủ vật lý và máy ảo đều có kích thước với số lượng tài nguyên GPU phù hợp. Theo dõi thời gian hoạt động của máy ảo và máy chủ lưu trữ có thể giúp nắm bắt các lần khởi động lại đột xuất. Các kết nối TCP tới VM cũng cần được theo dõi để có thể phát hiện và điều tra ngay lập tức kết nối và truyền lại. Và danh sách được tiếp tục! Điều quan trọng là các quản trị viên liên tục thu thập các số liệu này và phân tích chúng, vì phân tích đó có thể làm sáng tỏ các vấn đề hiệu suất tiềm năng và có thể cho phép quản trị viên giải quyết các vấn đề trước khi chúng ảnh hưởng đến doanh nghiệp.
Bài viết liên quan
- Top 10 chủ đề về Điện toán đám mây năm 2023
- Kiến trúc Cloud-Native là gì?
- Triển khai Generative AI hiệu quả với bộ giải pháp Private AI Foundation từ VMware và NVIDIA
- VMware hợp tác với NVIDIA mở khóa Generative AI cho các doanh nghiệp
- VMware Explore 2023: Tóm tắt các chủ đề trong Keynote
- Điện toán đám mây trở nên nhanh hơn với PowerEdge và AMD