
Ngay sau sự kiện ra mắt dòng máy chủ DGX A100 của NVIDIA, Supermicro cũng đã công bố loạt máy chủ GPU cho Data Center của mình với hiệu năng dẫn đầu ngành. Đây là các hệ thống đào tạo AI mạnh mẽ nhất với các nền tảng GPU NVIDIA A100 mới ra mắt. Các hệ thống mới này tận dụng công nghệ NVIDIA HGX™ thế hệ thứ 3, cũng như hỗ trợ đầy đủ cho GPU NVIDIA A100™ Tensor Core mới trên các máy chủ GPU của Supermicro với các hệ thống 1U, 2U và 4U dành cho Data Center.
Nền tảng HGX A100 tập hợp toàn bộ sức mạnh của GPU NVIDIA, mạng NVIDIA NVLink, mạng NVIDIA Mellanox InfiniBand và ngăn xếp phần mềm NVIDIA AI, HPC được tối ưu hóa hoàn toàn từ NGC để mang lại hiệu suất ứng dụng cao nhất. Với hiệu suất đầu cuối và tính linh hoạt, NVIDIA HGX A100 cho phép các nhà nghiên cứu và nhà khoa học kết hợp mô phỏng, phân tích dữ liệu và AI để thúc đẩy tiến bộ khoa học.


NVIDIA HGX A100 kết hợp GPU NVIDIA A100 Tensor Core với kết nối tốc độ cao để tạo thành máy chủ mạnh nhất thế giới. Với GPU A100 80GB, một HGX A100 duy nhất có bộ nhớ GPU lên đến 1,3 terabyte (TB) và băng thông bộ nhớ hơn 2 terabyte mỗi giây (TB / s), mang lại khả năng tăng tốc chưa từng có. HGX A100 mang đến tốc độ AI lên đến 20 lần so với các thế hệ trước với Tensor Float 32 (TF32) và tăng tốc 2,5 lần HPC với FP64. Được thử nghiệm đầy đủ và dễ dàng triển khai, HGX A100 tích hợp vào các máy chủ của đối tác để cung cấp hiệu suất được đảm bảo. NVIDIA HGX A100 với 16 GPU mang lại 10 petaFLOPS đáng kinh ngạc, tạo thành nền tảng máy chủ mở rộng quy mô được tăng tốc mạnh mẽ nhất thế giới dành cho AI và HPC.

NVIDIA HGX A100 với GPU A100 Tensor Core mang đến bước nhảy vọt tiếp theo trong nền tảng trung tâm dữ liệu tăng tốc, cung cấp khả năng tăng tốc chưa từng có ở mọi quy mô và cho phép các nhà đổi mới thực hiện công việc trong đời của họ. Và NVIDIA HGX A100 có 2 Platform chính là HGX A100 4-GPU và HGX A100 8-GPU để linh hoạt trong tùy chọn và phù hợp với nhiều yêu cầu sử dụng các các hệ thống về AI và HPC hiện nay
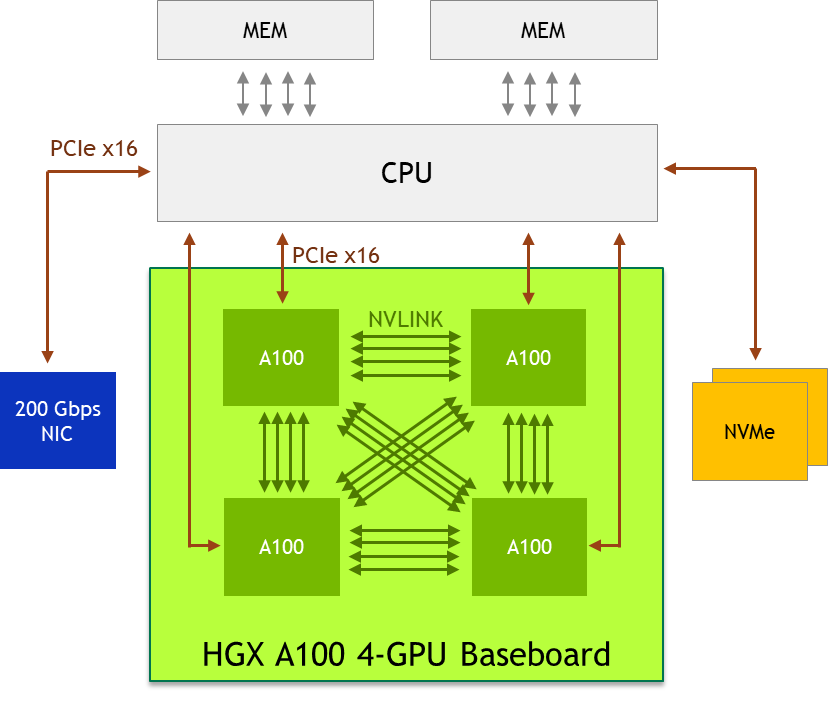
HGX A100 4-GPU được kết nối với NVLink để tăng tốc cho mục đích chung
Trong khi HGX A100 8-GPU với NVSwitch cung cấp hiệu suất nhanh nhất, có những tình huống ứng dụng trong đó nút máy chủ HGX A100 4-GPU là tối ưu. Ví dụ: bạn có thể gặp các trường hợp sau:
- Các khối lượng công việc mục tiêu, chẳng hạn như các ứng dụng khoa học nhất định, thích nhiều dung lượng CPU hơn để phù hợp với GPU A100 nhanh. Bốn GPU A100 cho hai CPU là một tỷ lệ cân bằng hơn.
- Một số trung tâm dữ liệu có nguồn điện tủ rack hạn chế do hạn chế về cơ sở hạ tầng. Nền tảng số lượng GPU thấp hơn với công suất máy chủ thấp hơn được ưu tiên.
- Một số quản trị viên trang web muốn phân bổ tài nguyên cho người dùng theo mức độ chi tiết của nút (với tối thiểu 1 nút) để đơn giản hóa. Một nút HGX A100 4-GPU cho phép độ chi tiết tốt hơn và giúp hỗ trợ nhiều người dùng hơn.
- Bốn GPU A100 trên bo mạch chủ GPU được kết nối trực tiếp với NVLink, cho phép kết nối đầy đủ. Mọi GPU A100 đều có thể truy cập bất kỳ bộ nhớ nào của GPU A100 khác bằng cổng NVLink tốc độ cao. Băng thông ngang hàng A100 đến A100 là 200 GB / s hai chiều, nhanh hơn 3 lần so với bus PCIe Gen4 x16 nhanh nhất.

Chế độ xem vật lý 4-GPU HGX A100. Kết hợp nền tảng máy chủ HGX A100 4-GPU với nhau
Để mang lại khả năng tăng tốc hiệu quả nhất, chúng tôi khuyên bạn nên xem xét thiết kế hệ thống sau:
- Sử dụng một CPU có số lượng lõi cao, đơn nếu khối lượng công việc không yêu cầu thêm dung lượng CPU. Điều này làm giảm BOM hệ thống và công suất và đơn giản hóa việc lập lịch trình.
- Giải phóng công tắc PCIe, Kết nối trực tiếp từ CPU đến GPU A100 để tiết kiệm BOM hệ thống và năng lượng.
- Trang bị cho nút một hoặc hai NIC và NVMe 200-Gb / s để đáp ứng nhiều trường hợp sử dụng khác nhau. Mellanox ConnectX-6 200Gb / s NIC là lựa chọn tốt nhất.
- Sử dụng bộ nhớ GPUDirect Storage , giúp giảm độ trễ đọc / ghi, giảm chi phí CPU và cho phép hiệu suất cao hơn.
HGX A100 8-GPU được kết nối với NVSwitch để có thời gian giải quyết nhanh nhất
Bảng điều khiển 8-GPU HGX A100 đại diện cho khối xây dựng chính của nền tảng máy chủ HGX A100. Hình ảnh cho thấy bo mạch chủ chứa tám GPU A100 Tensor Core và sáu nút NVSwitch. Mỗi GPU A100 có 12 cổng NVLink và mỗi nút NVSwitch là một công tắc NVLink hoàn toàn không chặn kết nối với tất cả tám GPU A100.
Cấu trúc liên kết lưới được kết nối đầy đủ này cho phép mọi GPU A100 nói chuyện với bất kỳ GPU A100 nào khác ở tốc độ hai chiều NVLink đầy đủ là 600 GB / s, gấp 10 lần băng thông của bus PCIe Gen4 x16 nhanh nhất. Hai tấm nền cũng có thể được kết nối ngược nhau bằng cách sử dụng NVSwitch to NVLink, cho phép kết nối hoàn toàn 16 GPU A100.
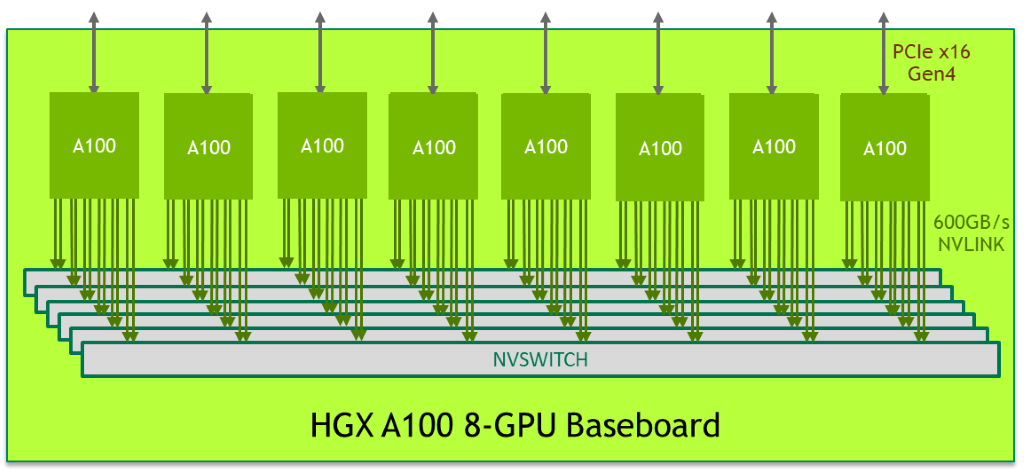
Sơ đồ logic của bo mạch chủ HGX A100 8-GPU. 
Chế độ xem vật lý 8-GPU HGX A100. Kết hợp nền tảng máy chủ HGX A100 8-GPU với nhau
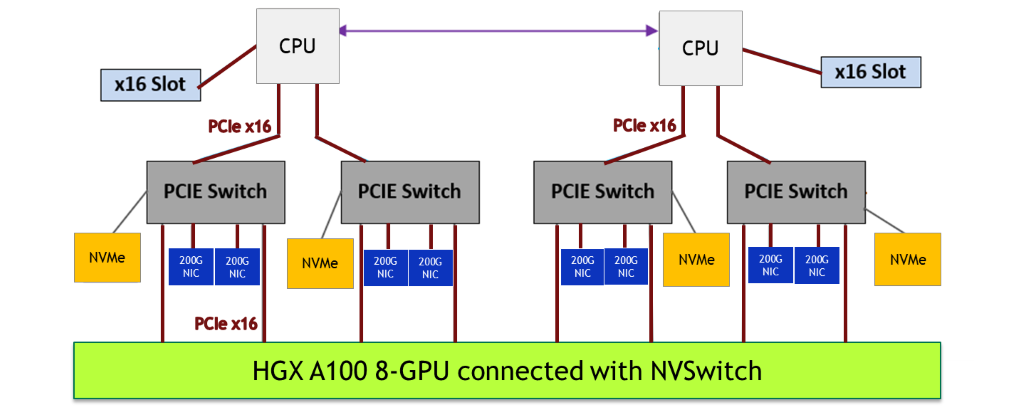
Với khối xây dựng bo mạch chủ GPU, các đối tác hệ thống máy chủ NVIDIA tùy chỉnh phần còn lại của nền tảng máy chủ theo các nhu cầu kinh doanh cụ thể: hệ thống con CPU, mạng, lưu trữ, nguồn, hệ số hình thức và quản lý nút. Để mang lại hiệu suất cao nhất, chúng tôi khuyên bạn nên xem xét thiết kế hệ thống sau:
- Chọn hai CPU máy chủ cao cấp nhất để ghép nối với tám GPU A100, để theo kịp A100.
- Sử dụng nhiều liên kết PCIe. Sử dụng tối thiểu bốn liên kết PCIe x16 giữa hai CPU và tám GPU A100, để đảm bảo có đủ băng thông cho CPU đẩy lệnh và dữ liệu vào GPU A100.
- Để có hiệu suất đào tạo AI tốt nhất trên quy mô lớn (nhiều nút cùng chạy một công việc đào tạo duy nhất), hiệu suất mạng giữa các nút là rất quan trọng. Sử dụng tỷ lệ GPU A100 lên đến 1: 1 cho thẻ giao diện mạng (NIC). Mellanox ConnectX-6 200-Gb / s NIC là lựa chọn tốt nhất.
- Gắn bộ lưu trữ NIC và NVMe vào công tắc PCIe và đặt nó gần GPU A100. Sử dụng cấu trúc liên kết cây PCIe nông và cân bằng. Công tắc PCIe cho phép truyền ngang hàng nhanh nhất từ NIC và NVMe vào và ra khỏi GPU A100.
- Sử dụng bộ nhớ GPUDirect Storage , giúp giảm độ trễ đọc / ghi, giảm chi phí CPU và cho phép hiệu suất cao hơn.
Lợi ích của NVSwitch
Bảng điều khiển 8-GPU HGX A100 mang thiết kế NVSwitch mới nhất. Bên cạnh việc cho phép giao tiếp ngang hàng A100-A100 nhanh nhất ở tốc độ 600 GB / giây, NVSwitch còn giúp cải thiện năng suất, cho phép các trường hợp sử dụng mới và nâng cao tính linh hoạt khi triển khai:
- Dễ lập trình hơn —Bạn không cần phải lo lắng về cấu trúc liên kết cụ thể giữa các GPU A100. Bất kỳ GPU A100 nào cũng có thể nói chuyện với bất kỳ GPU A100 nào khác ở tốc độ NVLink 600 GB / s đầy đủ. Bạn có thể tập trung nhiều thời gian hơn vào việc giải quyết khoa học và bớt thời gian lo lắng về việc triển khai hệ thống cụ thể.
- Các mô hình AI lớn hơn nhiều — Các mô hình AI lớn hơn thường giúp cải thiện độ chính xác của dự đoán. Mô hình song song chia thành một mô hình lớn và phân phối vào bộ nhớ của các GPU A100 khác nhau. NVSwitch đảm bảo rằng giao tiếp cường độ cao trong mô hình không phải là một nút cổ chai. Mô hình song song hiện khả thi hơn.
- Tách biệt nhiều đối tượng sử dụng linh hoạt —Khi nhiều người dùng chia sẻ hệ thống GPU HGX A100, với mỗi người dùng sở hữu một hoặc nhiều GPU A100, nút NVSwitch có thể tắt các cổng NVLink để cách ly người thuê, trong khi vẫn duy trì tốc độ NVLink ngang hàng đầy đủ giữa các GPU A100 mà một người thuê riêng lẻ sở hữu.
Đối với những khối lượng công việc khắt khe nhất, Supermicro xây dựng các hệ thống có hiệu suất cao nhất, nhanh nhất trên thị trường dựa trên GPU NVIDIA A100 ™ Tensor Core. Supermicro hỗ trợ một loạt các nhu cầu của khách hàng với các hệ thống được tối ưu hóa cho nền tảng HGX ™ A100 8-GPU và HGX ™ A100 4-GPU mới. Với phiên bản mới nhất của công nghệ NVIDIA® NVLink ™ và NVIDIA NVSwitch ™, các hệ thống này có thể cung cấp hiệu suất lên đến 5 PetaFLOPS trong một hệ thống 4U duy nhất.
Hệ thống Supermicro với Chứng nhận NVIDIA HGX A100 và NVIDIA
Hệ thống Supermicro với công nghệ NVIDIA HGX A100 4-GPU và 8-GPU được chứng nhận NVIDIA. Các hệ thống này đã vượt qua các bài kiểm tra chứng nhận NVIDIA để chạy như một máy chủ duy nhất và chạy nhiều máy chủ sử dụng mạng 200 gigabit, hỗ trợ vùng chứa phần mềm và khuôn khổ AI từ danh mục NVIDIA NGC. Dịch vụ hỗ trợ NGC có sẵn để giúp khách hàng phát triển và triển khai các hệ thống AI và HPC chạy trên các máy chủ Supermicro này. Danh mục Server Supermicro này gồm có các SKU: AS -2124GQ-NART (AMD); AS -4124GO-NART (AMD) và SYS-420GP-TNAR (INTEL).

Là nền tảng trung tâm dữ liệu cân bằng cho các ứng dụng HPC và AI, hệ thống 2U 2124GQ-NART mới của Supermicro tận dụng bo mạch GPU NVIDIA HGX A100 4 với bốn GPU NVIDIA A100 Tensor Core gắn trực tiếp và sử dụng PCI-E 4.0 cho hiệu suất tối đa, cùng với liên kết NVIDIA NVLink ™ cho kết nối GPU-to-GPU tốc độ cao. Hệ thống GPU tiên tiến này tăng tốc hiệu suất tính toán, kết nối mạng và lưu trữ với sự hỗ trợ cho PCI-E 4.0 x8 và tối đa bốn khe cắm mở rộng PCI-E 4.0 x16, hỗ trợ GPUDirect RDMA (Remote Direct Memory Access) tốc độ cao như InfiniBand™ HDR™, hỗ trợ băng thông lên tới 200Gbps.
Được tối ưu hóa cho AI và học máy, hệ thống 4U AS-4124GO-NART (AMD) và SYS-420GP-TNAR (INTEL) mới của Supermicro hỗ trợ tám GPU A100 Tensor Core, lý tưởng cho đào tạo học sâu quy mô lớn và các ứng dụng mô hình mạng thần kinh. Hệ thống GPU 4U mới có bo mạch chủ 8-GPU NVIDIA HGX A100, lên đến sáu NVMe U.2 và hai NVMe M.2, 10 I / O PCI-E 4.0 x16, với hỗ trợ AIOM độc đáo của Supermicro giúp tăng cường giao tiếp 8-GPU và luồng dữ liệu giữa các hệ thống thông qua các ngăn xếp công nghệ mới nhất như NVIDIA NVLink và NVSwitch, GPUDirect RDMA, GPUDirect Storage và NVMe-oF trên InfiniBand.
Hệ thống 4U này có một bo mạch GPU NVIDIA HGX A100 với tám GPU A100 được kết nối với nhau bằng NVIDIA NVSwitch™ cho băng thông GPU-to-GPU tối đa lên đến 600GB/s và tám khe cắm mở rộng cho mạng tốc độ cao GPUDirect RDMA. Lý tưởng cho đào tạo học sâu, các trung tâm dữ liệu có thể sử dụng nền tảng mở rộng này để tạo ra AI thế hệ tiếp theo và tối đa hóa năng suất của các nhà khoa học dữ liệu
Kết luận
Hệ thống Supermicro với NVIDIA HGX A100 cung cấp một bộ giải pháp linh hoạt để hỗ trợ GPU NVIDIA NGC và NVIDIA A100, cho phép phát triển và phân phối AI để chạy các mô hình AI nhỏ và lớn. Sử dụng GPU NVIDIA A100 có hiệu suất cao nhất, các nhà phát triển giảm thiểu thời gian quý báu để chạy các mô hình AI của họ, cung cấp các tính năng AI nhanh chóng và hiệu quả về chi phí vào các sản phẩm và dịch vụ mới và hiện có.
NVIDIA đang hợp tác chặt chẽ với Supermicro để đưa nền tảng máy chủ HGX A100 lên đám mây để linh hoạt hơn trong việc cung cấp nền tảng HGX A100 này đến với khách hàng và họ mong muốn đưa công cụ máy tính mạnh mẽ nhất này vào tay bạn, giúp bạn giải quyết những thách thức cấp bách nhất trên thế giới trong kinh doanh và nghiên cứu nhanh nhất và hiệu quả nhất.
GPU Server NVIDIA HGX A100 của Supermicro
| Máy Chủ GPU SuperServer AS -2124GQ-NART | Máy Chủ GPU SuperServer SYS-420GP-TNAR | Máy Chủ GPU SuperServer AS-4124GO-NART | |
-90x68.jpg "Máy Chủ GPU SuperServer AS -2124GQ-NART")
|

|
|
|
| Đơn giá | 0 VNĐ | 0 VNĐ | 289.740.000 VNĐ |
| Mã hàng | A+ Server 2124GQ-NART | SuperServer SYS-420GP-TNAR | A+ Server 4124GO-NART |
| Thương hiệu | Supermicro | Supermicro | Supermicro |
| Server | |||
| CPU Sockets | 2 x Socket SP3 | 2 x Socket P+ | 2 x Socket SP3 |
| CPU Support | Dual AMD EPYC 7002 Series Processors, TDP up to 280W | Dual 3rd Gen Intel Xeon Scalable processors, TDP up to 270W | Dual AMD EPYC 7002 Series Processors, TDP up to 280W |
| RAM Support | 32 x DIMM slots; Up to 8TB 3DS ECC DDR4-3200MH SDRAM | 32 x DIMM slots; Up to 8TB DRAM; Up to 8TB Intel Optane Persistent Memory (up to 12TB with DRAM) | 32 x DIMM slots; Up to 8TB 3DS ECC DDR4-3200MH SDRAM |
| Drive Bays | 4 x 2.5" Hot-swap (SAS/SATA/NVMe Hybrid) | 6x 2.5 Hot-swap U.2 NVMe 2.5" drive bays | 6x 2.5 Hot-swap U.2 NVMe 2.5" drive bays |
| Form Factor | 2U | 4U | 4U |
| PCIe | 4 x PCI-E Gen 4 x16 (LP), 1 x PCI-E Gen 4 x8 (LP) | 10 x PCI-E Gen 4.0 X16 LP | 8x PCI-E 4.0 x16 via PCI-E switch; 1x PCI-E 4.0 x 16 LP; 1x PCI-E 4.0 x8 LP |
| Network Interface | 2 x 10GBase-T, 1 x 1Gbe IPMI | Flexible Networking via AIOM,1 dedicated IPMI LAN Port | Flexible Networking via AIOM,1 dedicated IPMI LAN Port |
| I/O Ports | 2 x USB 3.0, 1 x VGA Connector, 1 x COM port, 1 x TPM 2.0 | 2 x USB 3.0, 1 x VGA Connector, 1 x COM port | 2 x USB 3.0, 1 x VGA Connector, 1 x COM port |
| Power Supply | 2200W | 2200W | 2200W |
| Redundant Power | Yes | Yes | Yes |
| GPU Support | Up to 4 A100 SMX4 | Up to 8x A100 SMX4 | Up to 8x A100 SMX4 |
| NVMe | Yes | Yes | Yes |
| System Fan | 4 x Hot-swap heavy duty fans | 4 x heavy duty fans with optimal fan speed control | 4 x Hot-swap 11.5K RPM heavy duty fans |
 Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Với kinh nghiệm làm nhà phân phối chính thức máy chủ Supermicro từ năm 2005, Nhất Tiến Chung (NTC) tiên phong đem đến các giải pháp hạ tầng CNTT dựa trên danh mục phần cứng đa dạng và tối ưu chi phí đầu tư nhất từ Supermicro. Các máy chủ GPU và máy chủ lưu trữ hiệu năng cao chuyên dụng cho AI, Deep Learning, cấu hình tùy biến theo nhu cầu, được nhiều đối tác lựa chọn cho dự án của mình. Vui lòng liên hệ để được tư vấn giải pháp, hoàn toàn miễn phí.
Bài viết liên quan
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI
- NVIDIA GB200 NVL72: Tối đa hóa đào tạo và suy luận LLM với hàng nghìn tỷ tham số