











Mellanox Networking: AI hiệu quả cần kết nối nội bộ hiệu suất cao

InfiniBand tạo tiền đề cho các nền tảng Machine Learning hiệu quả nhất
Học máy (Machine Learning) là một trọng tâm của thế giới công nghệ ngày nay, cung cấp các giải pháp cho phép đưa ra quyết định tốt hơn và chính xác hơn dựa trên khối lượng lớn dữ liệu được thu thập. Học máy được ứng dụng cho một loạt các lĩnh vực từ bảo mật, tài chính, nhận dạng hình ảnh và giọng nói, đến xe hơi tự lái, chăm sóc sức khỏe và thành phố thông minh.
InfiniBand tăng tốc tất cả các framework phổ biến như TensorFlow, CNTK, Paddle, Pytorch và Apache Spark thông qua RDMA, đồng thời tiếp tục đổi mới và tăng tốc các giải pháp để thực hiện đào tạo phân tán nhanh nhất, có thể mở rộng nhất cho các mô hình lớn và mạnh mẽ.
Bằng việc cung cấp độ trễ thấp, băng thông cao, tốc độ truyền tin cao và giảm tải một cách thông minh, các kết nối InfiniBand là giải pháp tốc độ cao được triển khai nhiều nhất cho Machine Learning quy mô lớn, cả ở các hệ thống đào tạo và suy luận.
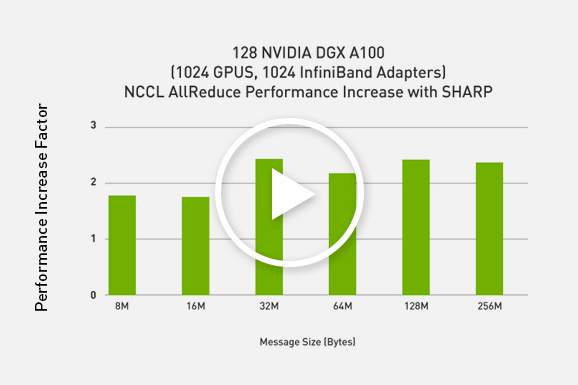
Tối đa hóa hiệu suất cho ML và DL phân tán với SHARP
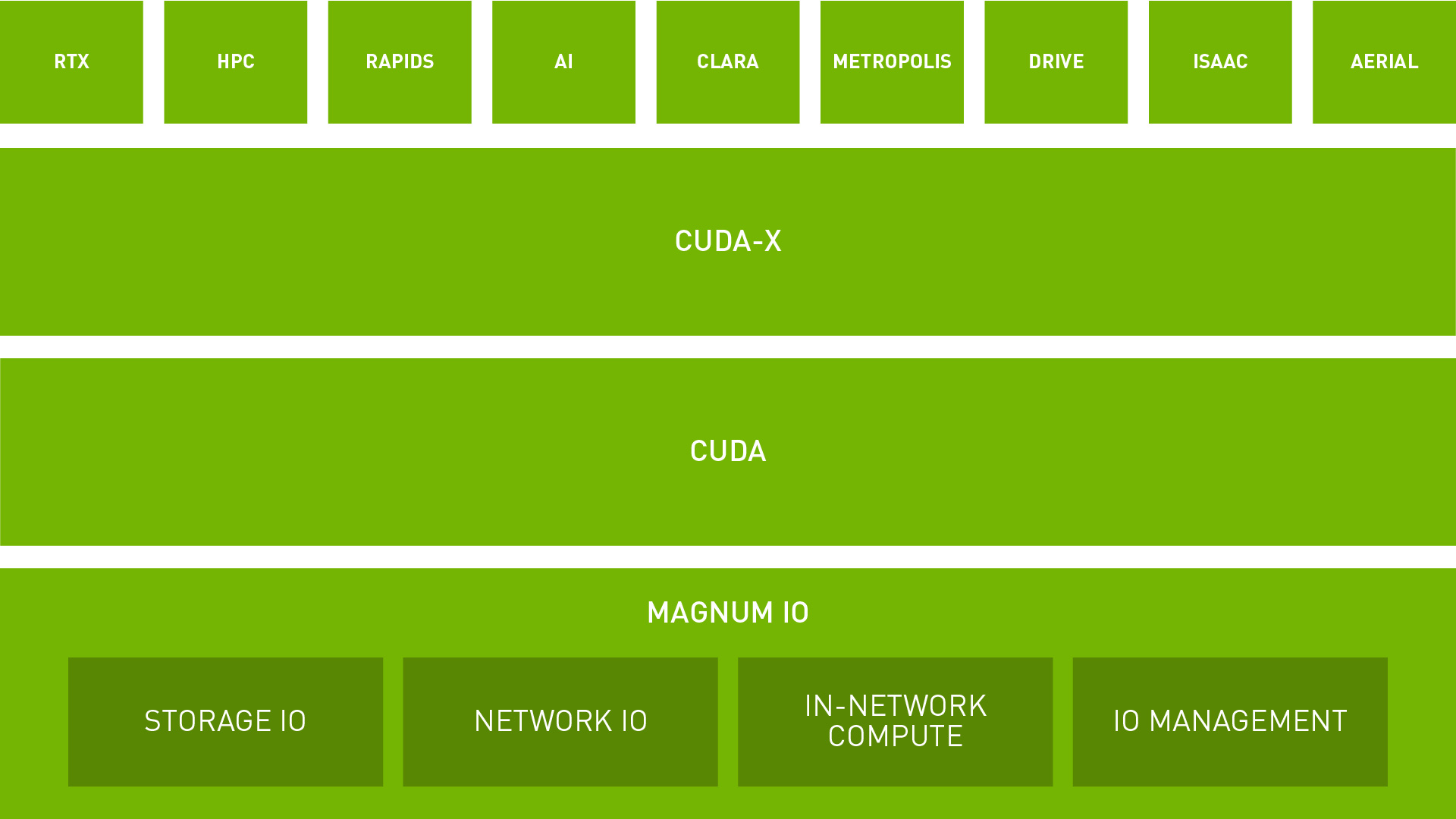
Tối đa hóa lưu trữ Data Center và hiệu suất Network IO với NVIDIA Magnum IO
Magnum IO sử dụng Storage IO, Network IO, In-network Compute và IO Management để đơn giản hóa và tăng tốc độ di chuyển, truy cập và quản lý dữ liệu cho các hệ thống đa GPU, đa node.
Magnum IO hỗ trợ các thư viện NVIDIA CUDA-X™ và việc sử dụng một dải các NVIDIA GPU cùng các cấu trúc liên kết phần cứng mạng tốt nhất để đạt được thông lượng tối ưu và độ trễ thấp.
→ Tìm hiểu thêm về Magnum IO
Thiết lập một tiêu chuẩn mới trong MLPerf
Các giải pháp đào tạo và suy luận của NVIDIA mang lại hiệu suất kỷ lục trong MLPerf, điểm chuẩn trong ngành về hiệu suất AI.
MLPerf là gì?
MLPerf là một tập hợp các nhà lãnh đạo AI từ các học viện, phòng thí nghiệm nghiên cứu, các ngành có nhiệm vụ “xây dựng các điểm chuẩn công bằng và hữu ích”. Chúng cung cấp các đánh giá không thiên vị về hiệu suất đào tạo và suy luận cho phần cứng, phần mềm và dịch vụ – tất cả đều được thực hiện trong các điều kiện quy định. Để đi đầu trong các xu hướng của ngành, MLPerf tiếp tục phát triển, tổ chức các thử nghiệm mới đều đặn và bổ sung khối lượng công việc mới đại diện cho sự hiện đại trong AI. Xem thêm
NVIDIA RAPIDS Accelerator và InfiniBand hỗ trợ mạnh mẽ cho Apache Spark 3.0

Khi các nhà khoa học dữ liệu chuyển đổi từ sử dụng phân tích truyền thống sang các ứng dụng AI với Apache Spark 3.0, InfiniBand cung cấp đường dẫn nhanh nhất để di chuyển dữ liệu giữa các node Spark từ xa và được kết hợp chặt chẽ với các hoạt động Spark Shuffle tận dụng framework giao tiếp UCX. Xem thêm
SHARPv2 mang lại hiệu suất cao nhất cho AI
Auto-Encoder là một mạng nơ-ron nhân tạo học cách sao chép đầu vào của nó thành đầu ra của nó. Nó có một lớp bên trong (ẩn) mô tả mã được sử dụng để đại diện cho đầu vào và nó được cấu thành bởi hai phần chính: bộ mã hóa ánh xạ đầu vào thành mã và bộ giải mã ánh xạ mã để tái tạo lại bản gốc đầu vào.
Các Auto-Encoder đa dạng, sử dụng phương pháp tiếp cận bất định để học cách đại diện ngầm và cho phép thiết kế các mô hình dữ liệu tổng hợp phức tạp và làm cho chúng phù hợp với các bộ dữ liệu lớn. Một số ví dụ thú vị bao gồm việc tạo ra hình ảnh của các khuôn mặt hư cấu, có thể là dành cho dịch vụ khách hàng trực tuyến hoặc các giáo sư trong một viện giáo dục trực tuyến hoặc tác phẩm nghệ thuật kỹ thuật số độ phân giải cao cho sự kiện.
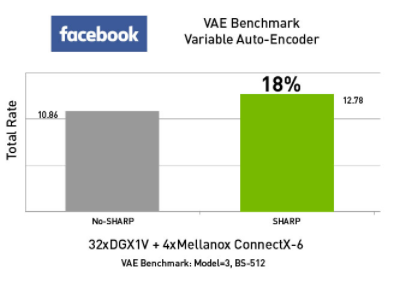
Công nghệ Mellanox SHARPv2 cải thiện đáng kể hiệu suất có thể mở rộng của VAE.
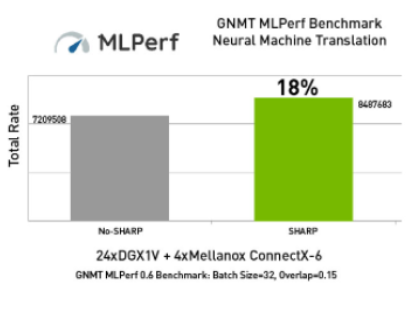
Google Neural Machine Translation (GNMT) là một hệ thống dịch máy nơ-ron do Google phát triển sử dụng mạng thần kinh nhân tạo để tăng tính trôi chảy và chính xác trong Google Translate.
GNMT cải thiện chất lượng bản dịch bằng cách áp dụng phương pháp dịch máy dựa trên ví dụ trong đó hệ thống học hỏi từ hàng triệu ví dụ.
Sự tích hợp được kết hợp chặt chẽ giữa NCCL® + SHARP plugin mới từ HPC-X™ thể hiện hiệu suất vượt trội cho GNMT.
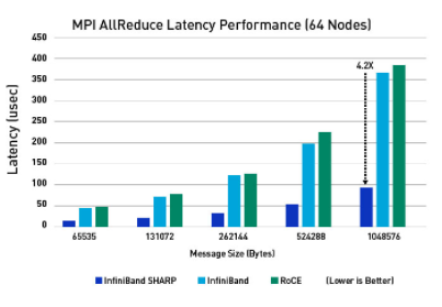
Lợi thế về hiệu suất của SHARPv2
Nhiều ứng dụng song song sẽ yêu cầu việc truy cập đến các kết quả đã được giảm lược đi trên tất cả các quy trình hơn là quy trình gốc. Trong một kiểu bổ sung tương tự của MPI_Allgather với MPI_Gather, MPI_Allreduce sẽ giảm các giá trị và phân phối kết quả cho tất cả các quy trình.
Độ trễ cũng như băng thông mạng rất quan trọng đối với nhiều khối lượng công việc AI bao gồm NLP. InfiniBand với công nghệ Mellanox SHARP giúp giảm đáng kể độ trễ cho các gói tin thường có kích thước lớn hơn. Ngay cả RDMA over Converged Ethernet cũng không phù hợp với các khả năng in-network computing của SHARP.
Hiệu suất tăng gấp 10 lần với NVIDIA Mellanox GPUDirect® RDMA

Được thiết kế đặc biệt cho nhu cầu tăng tốc GPU, GPUDirect RDMA cung cấp giao tiếp trực tiếp giữa các GPU NVIDIA trong các hệ thống từ xa. Điều này giúp loại bỏ các CPU hệ thống và các bản sao dữ liệu đệm cần thiết thông qua bộ nhớ hệ thống, dẫn đến hiệu suất tốt hơn gấp 10 lần.
NVIDIA DGX A100
NVIDIA DGX™ A100 là hệ thống chung cho tất cả khối lượng công việc AI, cung cấp mật độ tính toán, hiệu suất và tính linh hoạt chưa từng có trong hệ thống AI 5 petaFLOPS đầu tiên trên thế giới. NVIDIA DGX A100 có bộ tăng tốc tiên tiến nhất thế giới là GPU NVIDIA A100 Tensor Core và lên đến 10 Adapter HDR 200 Gb/s InfiniBand, cho phép các doanh nghiệp hợp nhất đào tạo và suy luận vào trong một hạ tầng AI dễ triển khai và thống nhất. Tìm hiểu thêm về NVIDIA DGX A100
Tham khảo các sản phẩm của Mellanox tại:
→ https://thegioimaychu.vn/thiet-bi-mang/mellanox
→ https://thegioimaychu.vn/linh-kien-may-chu/mellanox
Giới thiệu về Mellanox
Là một thành viên sau khi được NVIDIA mua lại vào tháng 4 năm 2020, Mellanox Technologies là nhà cung cấp hàng đầu về các giải pháp và dịch vụ kết nối thông minh trên Ethernet và InfiniBand cho máy chủ, hệ thống lưu trữ và hạ tầng siêu hội tụ. Các giải pháp kết nối thông minh của Mellanox làm tăng hiệu quả của trung tâm dữ liệu bằng cách cung cấp thông lượng cao nhất và độ trễ thấp nhất.
Nhất Tiến Chung (NTC) là nhà cung cấp các giải pháp hạ tầng Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là nhà phân phối chính thức của các hệ thống siêu máy tính cho AI với sức mạnh xử lý của GPU NVIDIA và mạng tốc độ cao từ Mellanox Technologies.

