
Sự tin tưởng của chúng ta đối với AI phần lớn sẽ phụ thuộc vào việc chúng ta hiểu nó như thế nào – Explainable AI, AI có thể giải thích được, hay XAI, giúp soi sáng chiếc “hộp đen” về độ phức tạp trong các mô hình AI.
Trong những năm gần đây có một ngành cũ mà mới đang dần phát triển trong lĩnh vực trí tuệ nhân tạo, Explainable AI, hay gọi tắt là XAI, với những thành tựu trong ngành này ta có thể giải mã các “hộp đen” của AI và như một hệ quả kèm sau đó, những rào cản được tạo ra bởi các “hộp đen” này cũng sẽ được giải tỏa. Khi đó giáo dục sẽ không còn an toàn nữa, khi đó AI sẽ thực sự có đủ tiềm năng để thay thế con người mà cụ thể hơn là các thầy cô giáo trong việc truyền đạt kiến thức.
Explainable AI là gì?
XAI là một tập hợp các công cụ và kỹ thuật được các tổ chức sử dụng để giúp mọi người hiểu rõ hơn tại sao một mô hình đưa ra các quyết định nào đó và cách thức hoạt động của mô hình. XAI là:
- Tập hợp các phương pháp tốt nhất: Nó tận dụng một số quy trình và quy tắc tốt nhất mà các nhà khoa học dữ liệu đã sử dụng trong nhiều năm để giúp những người khác hiểu cách đào tạo một mô hình. Biết được cách thức và dữ liệu nào hay một mô hình đã được đào tạo nào đó giúp chúng ta hiểu khi nào thì mô hình đó hoạt động và không hợp lý khi sử dụng mô hình đó. Nó cũng soi sáng những nguồn sai lệch mà mô hình có thể đã tiếp xúc.
- Tập hợp các nguyên tắc thiết kế: Các nhà nghiên cứu ngày càng tập trung vào việc đơn giản hóa việc xây dựng các hệ thống AI để làm cho chúng vốn dĩ dễ hiểu hơn.
- Một bộ công cụ: Khi các hệ thống trở nên dễ hiểu hơn, các mô hình đào tạo có thể được hoàn thiện thêm bằng cách kết hợp những kiến thức đó vào đó – và bằng cách cung cấp những kiến thức đó cho những người khác để đưa vào mô hình của họ.
Explainable AI hoạt động như thế nào?
Mặc dù vẫn còn nhiều tranh luận về việc tiêu chuẩn hóa các quy trình XAI, nhưng một số điểm chính giao thoa giữa các lĩnh vực đã triển khai nó:

- Chúng ta phải giải thích mô hình cho ai?
- Chúng ta cần một lời giải thích chính xác hay chính xác đến mức nào
- Chúng ta có cần giải thích mô hình tổng thể hay một quyết định cụ thể không?
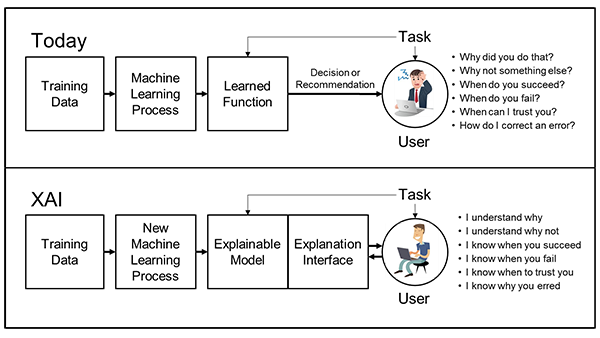 Nguồn: DARPA
Nguồn: DARPA
Các nhà khoa học dữ liệu đang tập trung vào tất cả những câu hỏi này, nhưng khả năng giải thích được tóm lại là: Chúng ta đang cố giải thích điều gì?
Giải thích phả hệ của mô hình:
- Mô hình đã được đào tạo ra như thế nào?
- Dữ liệu nào đã được sử dụng?
- Tác động của bất kỳ sai lệch nào trong dữ liệu đào tạo được đo lường và giảm thiểu như thế nào?
Những câu hỏi này tương ứng với việc khoa học dữ liệu sẽ giải thích bác sĩ phẫu thuật của bạn đã học ở trường nào – cùng với giáo viên của họ là ai, họ học gì và họ đạt điểm như thế nào. Làm đúng được những điều này là thuộc về quy trình xử lý và việc để lại vết trên giấy hơn là về bản thân AI thuần túy, nhưng điều quan trọng là thiết lập niềm tin vào một mô hình.
Mặc dù việc giải thích phả hệ của một mô hình nghe có vẻ khá dễ dàng, nhưng thực tế lại rất khó, vì nhiều công cụ hiện không hỗ trợ thu thập thông tin mạnh mẽ. NVIDIA cung cấp thông tin như vậy về các mô hình được đào tạo trước của mình. Chúng được chia sẻ trên danh mục NGC , một nền tảng trung tâm gồm các mô hình và SDK cho điện toán hiệu năng cao được tối ưu hóa bằng GPU, giúp các doanh nghiệp xây dựng ứng dụng của họ một cách nhanh chóng.
Giải thích mô hình tổng thể:
Đôi khi được gọi là khả năng diễn giải mô hình, đây là một lĩnh vực nghiên cứu đang rất được quan tâm. Hầu hết các giải thích mô hình rơi vào một trong hai hướng:
Trong một kỹ thuật đôi khi được gọi là “mô hình proxy”, các mô hình đơn giản hơn, dễ hiểu hơn như cây quyết định có thể được sử dụng để mô tả gần đúng mô hình AI một cách chi tiết hơn. Những giải thích này mang lại “cảm giác” về tổng thể mô hình, nhưng sự cân bằng giữa tính gần đúng và tính đơn giản của mô hình proxy vẫn là nghệ thuật hơn là khoa học.
Mô hình proxy luôn là một phép gần đúng và ngay cả khi được áp dụng tốt, nó có thể tạo cơ hội cho các quyết định trong đời thực rất khác so với những gì mong đợi từ các mô hình proxy.
Cách tiếp cận thứ hai là “thiết kế để có thể diễn giải”. Điều này hạn chế các tùy chọn thiết kế và đào tạo của mạng AI theo những cách cố gắng tập hợp mạng tổng thể ra khỏi các phần nhỏ hơn mà chúng ta buộc phải có hành vi đơn giản hơn. Điều này có thể dẫn đến các mô hình vẫn mạnh mẽ, nhưng với hành vi dễ giải thích hơn nhiều.
Tuy nhiên, điều này không hề dễ dàng và nó hy sinh một số mức độ hiệu quả và độ chính xác bằng cách loại bỏ các thành phần và cấu trúc khỏi hộp công cụ của nhà khoa học dữ liệu. Cách tiếp cận này cũng có thể yêu cầu sức mạnh tính toán nhiều hơn đáng kể.
Tại sao XAI giải thích tốt nhất các quyết định cá nhân
Lĩnh vực được hiểu rõ nhất của XAI là ra quyết định cá nhân: chẳng hạn tại sao một người không được chấp thuận cho vay.
Các kỹ thuật có tên như LIME và SHAP cung cấp các câu trả lời toán học rất đúng nghĩa đen cho câu hỏi này – và kết quả của phép toán đó có thể được trình bày cho các nhà khoa học dữ liệu, nhà quản lý, cơ quan quản lý và người tiêu dùng. Đối với một số dữ liệu – hình ảnh, âm thanh và văn bản – các kết quả tương tự có thể được hình dung thông qua việc sử dụng “sự chú ý” trong các mô hình – buộc chính mô hình phải thể hiện công việc của mình.
Trong trường hợp các giá trị Shapley được sử dụng trong SHAP, có một số bằng chứng toán học về các kỹ thuật cơ bản đặc biệt hấp dẫn dựa trên lý thuyết trò chơi được thực hiện vào những năm 1950. Có nghiên cứu tích cực trong việc sử dụng những giải thích này về các quyết định riêng lẻ để giải thích tổng thể mô hình, chủ yếu tập trung vào phân cụm và buộc các ràng buộc về độ mượt khác nhau đối với phép toán cơ bản.
Hạn chế của các kỹ thuật này là chúng hơi tốn kém về mặt tính toán. Ngoài ra, nếu không có nỗ lực đáng kể trong quá trình đào tạo mô hình, kết quả có thể rất nhạy cảm với các giá trị dữ liệu đầu vào. Một số người cũng cho rằng vì các nhà khoa học dữ liệu chỉ có thể tính toán các giá trị Shapley gần đúng, các đặc điểm hấp dẫn và có thể chứng minh được của những con số này cũng chỉ gần đúng – làm giảm mạnh giá trị của chúng.
Trong khi các cuộc tranh luận lành mạnh vẫn còn, rõ ràng là bằng cách duy trì một phả hệ mô hình phù hợp, áp dụng phương pháp giải thích mô hình cung cấp sự rõ ràng cho lãnh đạo cấp cao về các rủi ro liên quan đến mô hình và theo dõi kết quả thực tế với các giải thích riêng lẻ, các mô hình AI có thể được xây dựng với sự hiểu biết rõ ràng hành vi cư xử.
Một lời giải thích tốt cần những gì?
Sự dễ hiểu, đúng vậy, cái chúng ta cần là giải thích cho người khác, có thể là đồng nghiệp hoặc khách hàng – người có ít kiến thức về AI hiểu cách mô hình hoạt động thì lời giải thích này phải ở mức dễ hiểu nhất; chúng ta không thể nào vẽ biểu đồ như vầy cho một mô hình cây quyết định để giải thích được.
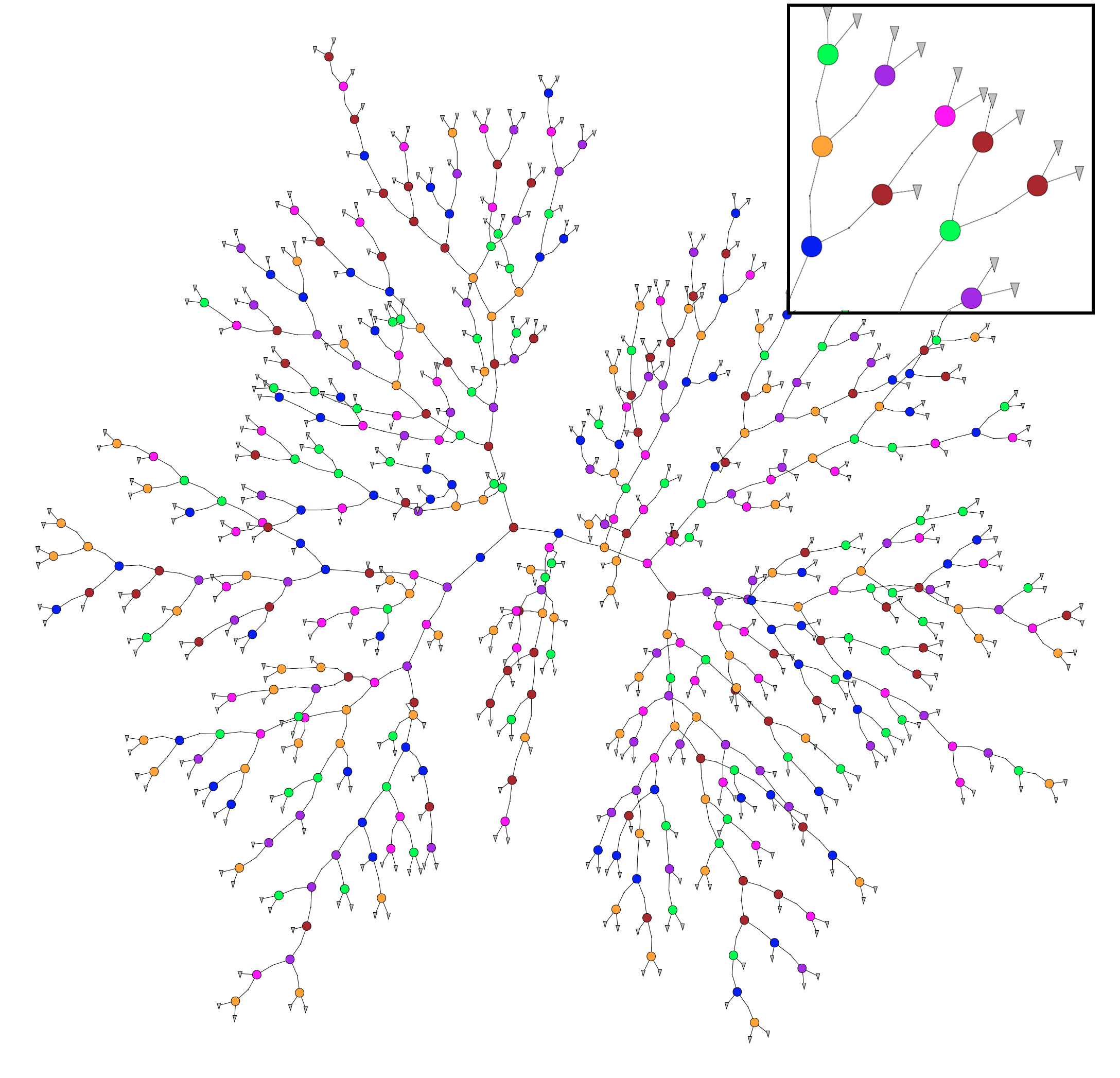
Bạn không thể nào hình dung được nó là gì cho dù có phóng to lên, quá phức tạp. Ít nhất nó phải ở mức như hình dưới:
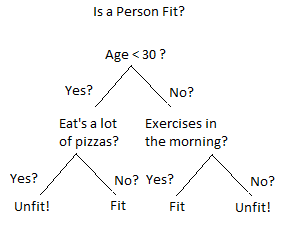
Trực quan, rõ ràng và tất nhiên là dễ hiểu hơn sơ đồ phía trên nhiều lần.
Sau khi có một lời giải thích cho con người có thể hiểu thì tiếp theo cái chúng ta cần là sự đúng đắn; ta đưa ra sự giải thích cho một trường hợp nhất định một dữ liệu kiểm tra nhất định nhưng không có nghĩa là mẫu kiểm tra này đại diện được cho toàn bộ mô hình. Bởi vì ở riêng từng trường hợp đặc trưng này có thể ảnh hưởng lớn nhất nhưng không thể nào quy chụp đặc trưng này cho toàn bộ các dữ liệu trong tập kiểm thử được. Nói đi cũng phải nói lại, một mẫu kiểm thử không đủ để đại diện cho toàn mô hình thì ta chọn nhiều mẫu dữ liệu kiểm thử và cần phải đảm bảo rằng một số dữ liệu chúng ta chọn ra này là những dữ liệu có thể đại diện được cho mô hình.
Tiêu chí cuối cùng cũng quan trọng không kém là phương pháp giải thích mô hình đang thực hiện phải có được tính khái quát, tức là một phương pháp giải thích cần sử dụng được cho nhiều loại mô hình khác nhau. Như chúng ta đã biết hiện tại có rất nhiều mô hình khác nhau, chúng ta không thể nào với mỗi mô hình lại cho ra một phương pháp giải thích được; cái ta cần là một cái gì đó tổng quát.
Sự dễ hiểu vs Độ chính xác
Ở đây ta có hai hướng để đưa ra lời giải thích cho mô hình để đảm bảo đầy đủ các tiêu chí được đề cập bên trên.
Một là xây dựng những mô hình tường minh dễ hiểu, như các mô hình hồi quy, đa phần là các công thức toán học mà đã là công thức thì có thể giải thích một cách dễ dàng được. Ví dụ với mô hình Hồi Quy Tuyến Tính (Linear Regression) về cơ bản là một phương trình có dạng
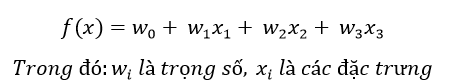
Đặc trưng nào có trọng số lớn thì có ảnh hưởng, tầm quan trọng lớn hơn và ngược lại; vô cùng đơn giản dễ hiểu.
Nhưng các mô hình đơn giản lại không đạt được độ chính xác cao ở các bài toán phức tạp bằng các mạng học sâu. Chúng ta có một sự đánh đổi giữa độ dễ hiểu và độ chính xác trong các dự đoán của mô hình ở đây.
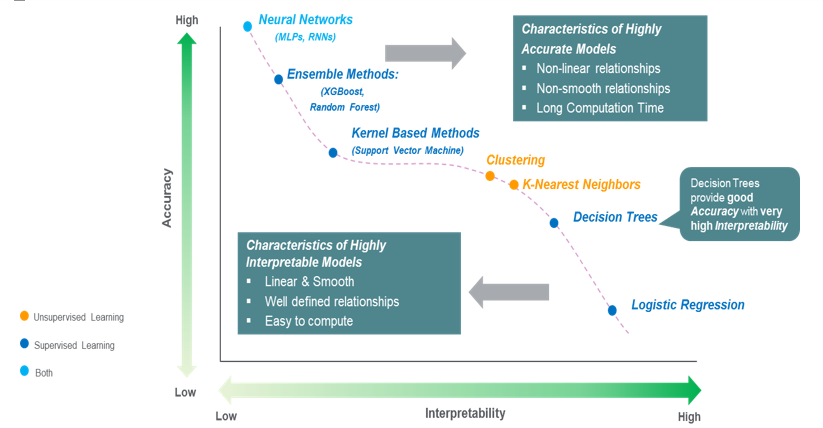
Những mô hình càng đạt được đô chính xác cao, theo một nghĩa nào đó là càng tốt thì sự dễ hiểu càng thấp. Sự dễ hiểu và độ chính xác đối với các mô hình học máy, học sâu đang là hai đại lượng tỷ lệ nghịch với nhau. Mặt khác, khi gặp trường hợp có dữ liệu quá phức tạp hoặc quá nhiều đặc trưng, như những bài toán phân loại văn bản thì mỗi từ cũng đã là một đặc trưng rồi và ta có cả trăm cả ngàn từ, thì những mô hình dễ hiểu cũng sẽ không còn dễ hiểu nữa.
Thế có cách nào để giúp chúng ta có thể hiểu được các mô hình tốt khi bản thân chúng như những “black-box” – hộp đen máy bay. Câu trả lời là có và cách tiếp cận này trong việc giải thích các mô hình được gọi là các phương pháp hậu học (post-hoc).
Một số phương pháp
Trong hướng tiếp cận hậu học thì có vài phương pháp khá thú vị như LIME (Local Interpretable Model-agnostic Explanations), SHAP (Shapley Additive exPlanations), Influence Functions, Integreated Gradient, ….
LIME là phương pháp đưa việc to hóa nhỏ, thay vì giải thích cho toàn cục thì ta đưa sự việc về địa phương (local) và biểu thị ra cho bạn phần nào trong dữ liệu ảnh hương nhiều nhất tới dự đoán của mô hình

Như hình trên, mô hình dự đoán đó là chó Labrador bởi vì các điểm ảnh ở mặt của chú chó này.
Trong khi đó SHAP là phương pháp sử dụng kiến thức từ Lý thuyết trò chơi và Thống kê để đưa ra được mức độ ảnh hưởng của các đặc trưng.

Theo ảnh trên thì các điểm màu hồng chính là các điểm ảnh quan trọng, những điểm để “đại diện” cho nhãn được xem xét. Có thể với hình cầy vằn (cầy Meerkat) thì phần mặt chính là điểm giúp nhận diện tốt nhất; còn thử với nhãn là cầy lỏn (cầy Mangut) thì gần như không có điểm ảnh nào đại diện cho nhãn này cả.
Tạm kết
Như vậy, chúng ta đã rõ hơn một số tiêu chí cho việc giải thích mô hình cũng như biết về một số phương pháp giải thích. Thế những phương pháp này hoạt động như thế nào? Tại sao nó có thể chỉ ra chính xác những điểm ảnh đại diện cho nhãn? Liệu với dữ liệu văn bản, dữ liệu dạng bảng thì các phương pháp này sẽ biểu diễn các đặc trưng ra sao?
Nguồn Tổng hợp
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI