
Các doanh nghiệp đang phát triển hệ thống để chạy khối lượng công việc AI cường độ cao có hai lựa chọn để thực hiện công việc nặng nhọc: kiến trúc CPU (đơn vị xử lý trung tâm) truyền thống hoặc GPU pipeline chuyên biệt. Hầu hết mọi người đều hiểu rằng trong bối cảnh của doanh nghiệp hiện đại, chạy song song nhiều khối lượng công việc học sâu là điểm mấu chốt của GPU. Tuy nhiên, điều quan trọng là phải hiểu rõ mức độ đầy đủ của các ứng dụng AI / học sâu và cách chọn loại bộ xử lý phù hợp cho một khối lượng công việc nhất định.
CPU và GPU: Cách chúng hoạt động
CPU được thiết kế để ưu tiên tốc độ hoạt động cho các tính toán tuần tự, điều này cho phép chúng thực hiện các tập lệnh đa dạng. Khi được giao đúng nhiệm vụ, CPU sẽ thực hiện với tốc độ nhanh vượt trội, được đo bằng tốc độ xung nhịp. Ngày nay, CPU vẫn là phần cốt lõi của bất kỳ thiết bị máy tính nào. Nó xử lý các hướng dẫn cơ bản và phân bổ các tác vụ phức tạp hơn cho các chip cụ thể khác trên bo mạch chủ. Lưu ý rằng GPU không thể thay thế cho CPU.
GPU được thiết kế để nhanh chóng kết xuất hình ảnh, video, hình ảnh và hiển thị 2D / 3D có độ phân giải cao. GPU bắt đầu từ phục vụ cho xử lý đồ họa, nhưng việc sử dụng chúng đã phát triển thành một trong những thành phần cốt lõi của học sâu / AI. GPU được thiết kế để xử lý hiệu quả các hoạt động hàng loạt được thực hiện song song. Chúng được thiết kế với nhiều lõi tính toán hơn rất nhiều so với CPU, đây là một kiến trúc lý tưởng cho các tác vụ tính toán lặp đi lặp lại, có độ song song cao và duy nhất.
Sự khác biệt chính giữa kiến trúc CPU và GPU là CPU được thiết kế để xử lý nhanh chóng một loạt các phép tính phức tạp được đo bằng tốc độ xung nhịp của CPU và GPU được thiết kế để xử lý nhanh chóng nhiều tác vụ đơn giản và cụ thể đồng thời. CPU có ít lõi hơn với tốc độ xử lý cao. GPU có hàng nghìn lõi và có tốc độ tương đối chậm hơn so với CPU. Vì GPU có nhiều lõi hơn và có thể thực hiện các hoạt động song song trên nhiều tập dữ liệu, chúng không bắt kịp với tốc độ xử lý thường cần cho các tác vụ phi đồ họa, chẳng hạn như học máy và tính toán khoa học.
GPU được sử dụng khi nào?
GPU lý tưởng để xử lý song song và đã trở nên được ưu tiên để đào tạo các mô hình AI: chúng hoàn toàn phù hợp với nhu cầu của một quy trình đòi hỏi các hoạt động gần như giống hệt nhau được thực hiện đồng thời trên tất cả các mẫu dữ liệu. Kích thước tập dữ liệu đang tăng gần như theo cấp số nhân và sự song song lớn được cung cấp bởi GPU dẫn đến việc thực hiện các tác vụ này nhanh hơn.
GPU được thiết kế để vượt trội trong các ứng dụng yêu cầu xử lý nhiều phép tính song song, đó là tỷ lệ áp đảo của các ứng dụng AI doanh nghiệp:
- Học sâu được tăng tốc và các hoạt động AI với đầu vào dữ liệu song song lớn
- Các thuật toán suy luận và đào tạo AI truyền thống
- Mạng nơ-ron cổ điển
Nói tóm lại, khi yêu cầu sức mạnh tính toán thô để xử lý dữ liệu không có cấu trúc hoặc phần lớn giống hệt nhau, thì GPU là giải pháp được ưu tiên.
Lấy ví dụ như GPU A100 mới của Nvidia. A100 có GPU 7nm đầu tiên của NVIDIA, GA100. GPU này được trang bị 6912 nhân CUDA và 40GB bộ nhớ HBM2. GPU này cũng nằm trên thẻ đầu tiên có giao diện PCIe 4.0 ngoài form factor SXM4 chuyên biệt và nó cũng nhanh không kém. Vì phiên bản PCIe có mức tiêu thụ điện năng thấp hơn (250W so với 400W trong phiên bản SXM4), nên hiệu suất sẽ giảm 10%. Tuy nhiên, điều đó nhanh chóng được thu lại nhờ chi phí điện năng và làm mát thấp hơn. Bộ xử lý đồ họa GA100 là một chip lớn với diện tích khuôn 826 mm² và 54,2 tỷ bóng bán dẫn. Nó có 6912 đơn vị tô bóng, 432 đơn vị ánh xạ họa tiết và 160 ROP. Ngoài ra còn có 432 lõi tensor, giúp cải thiện tốc độ của các ứng dụng học máy. NVIDIA đã ghép nối bộ nhớ HBM2E 40 GB với A100 SXM4, được kết nối bằng giao diện bộ nhớ 5120-bit. GPU hoạt động ở tần số 1410 MHz và bộ nhớ chạy ở tần số 1215 MHz. A100 được tối ưu hóa cho các hoạt động tensor, bao gồm các định dạng TF32 và FP64 mới có độ chính xác cao hơn và các phép tính 8-bit có độ chính xác thấp hơn để suy luận.
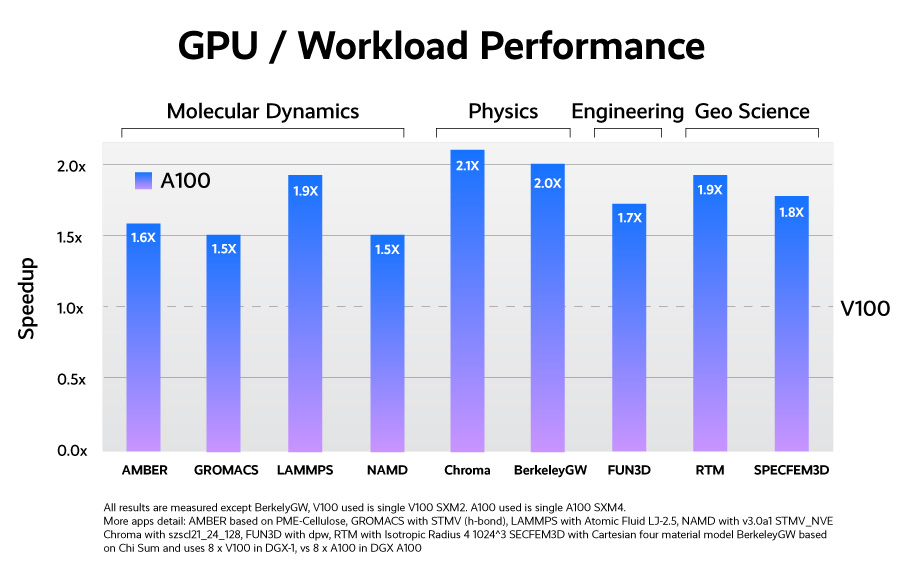
GPU A100 nhận được lợi thế 250% so với GPU Volta 12nm trước đó của nó ở hiệu suất dấu chấm động chính xác kép cao nhất. Trong khối lượng công việc của HPC, tốc độ thực hiện dao động trong khoảng 1,5 lần đến 2,1 lần so với phiên bản tiền nhiệm.
GPU đã phát triển đáng kể so với 30 năm trước, khi chúng được sử dụng chủ yếu trong máy tính cá nhân. Khi hiệu suất và mật độ tăng lên, nó đã chuyển đổi thành các máy trạm chuyên nghiệp, sau đó đến các máy chủ và bây giờ thành các giá đỡ trung tâm dữ liệu. Khi ngày càng có nhiều ứng dụng chạy trên đám mây và trung tâm dữ liệu, thì GPU sẽ trở thành một yếu tố thiết yếu của kiến trúc và hệ thống. Sức mạnh GPU ngày càng tăng được thể hiện qua GPU Nvidia A100, có thể được chia thành 7 phiên bản riêng biệt (GPU đa phiên bản) để có thể thúc đẩy việc sử dụng xử lý GPU được cải thiện và cung cấp nhiều khối lượng công việc khác nhau trong trung tâm dữ liệu.
CPU được sử dụng khi nào?
Trường hợp sử dụng cho các CPU trong vai trò AI doanh nghiệp hẹp hơn và chuyên biệt hơn. Các tác vụ có nhiều thuật toán khó chạy song song có thể phù hợp hơn với CPU, bao gồm:
- Đào tạo và suy luận các hệ thống gợi ý có yêu cầu bộ nhớ lớn hơn cho nhiều layers bên trong.
- Máy học và các thuật toán suy luận thời gian thực không dễ dàng song song hóa
- Mạng nơ-ron lặp lại dựa trên dữ liệu tuần tự
- Các mô hình mẫu dữ liệu kích thước lớn, bao gồm dữ liệu 3D để đào tạo và suy luận
CPU phù hợp hơn với các tác vụ sử dụng các thuật toán tuần tự và để thực hiện các phép tính thống kê phức tạp, tuy nhiên các loại tác vụ này ít phổ biến hơn trong các ứng dụng AI doanh nghiệp ngày nay. Hầu hết các doanh nghiệp thích tốc độ và hiệu quả của GPU hơn là sự chuyên môn hóa của CPU. Tuy nhiên, có những nhà khoa học dữ liệu đang suy nghĩ lại về cách các thuật toán AI được phát triển, có khả năng dựa vào logic (xử lý nối tiếp) hơn là tính toán thống kê.
CPU là thành phần dẫn dắt của toàn hệ thống, được thiết kế đặc biệt để cho phép nó lập kế hoạch và thực thi lập lịch cho tất cả các thành phần hệ thống và tốc độ xung nhịp của các core. Điều này giúp chúng thực hiện tốt các bài toán đơn, phức tạp trong thời gian ngắn. Khi thực hiện rất nhiều tác vụ nhỏ cùng một lúc, chẳng hạn như hiển thị 300.000 hình tam giác và tự động chuyển đổi chúng theo yêu cầu, các CPU bắt đầu bộc lộ những hạn chế của chúng, đặc biệt là trong các tính toán mạng nơ-ron ResNet.
Số lượng lõi trong một bộ xử lý đang tăng lên. Các bộ xử lý này trong một bộ xử lý có từ 2 đến 64 lõi. AMD Ryzen Threadripper 3970X có 32 lõi có khả năng xử lý 64 luồng. AMD Epyc 7702 có 64 lõi và 128 luồng. Lợi ích của việc có nhiều lõi là hệ thống có thể xử lý nhiều luồng dữ liệu hoặc luồng riêng biệt chạy độc lập với nhau. Kiến trúc này làm tăng đáng kể tài nguyên và hiệu suất của một hệ thống đang chạy các ứng dụng đồng thời và nhiều tác vụ trong trung tâm dữ liệu. Ngày càng có nhiều nhà phát triển khám phá sự phức tạp của việc viết mã để thực hiện trong các môi trường điện toán đa luồng, ảo hóa và chứa trong môi trường song song.
CPU và GPU cùng nhau
Trong các trung tâm dữ liệu, việc tận dụng cả CPU và GPU là điều cần thiết. Định luật Moore đang chậm lại, và như vậy, để nâng cấp và mở rộng quy mô, hiệu suất tổng thể của các hệ thống sẽ cần phụ thuộc vào một hệ sinh thái hoàn chỉnh gồm phần cứng, phần mềm và các nhà phát triển. Khối lượng công việc của AI sẽ đòi hỏi nhiều công nghệ silicon khác nhau và các giải pháp này sẽ cần phải kết hợp các bộ xử lý được xây dựng có mục đích và bộ xử lý đa năng vào các máy chủ và thiết bị này để đạt được hiệu suất, hiệu quả và chi phí tốt hơn – từ trung tâm dữ liệu cho đến rìa mạng.
Kết nối băng thông cao, tiết kiệm năng lượng của NVIDIA cho phép giao tiếp CPU với GPU và GPU với GPU cực nhanh. Các siêu máy tính DGX tận dụng lợi thế của giao tiếp GPU với GPU. Thiết kế SXM4 cho phép GPU hoạt động ngoài các giới hạn của bus PCIe để chúng có thể đạt được tiềm năng hiệu suất tối đa. Để tăng IO giữa các GPU, giao tiếp nội bộ Nvidia NVLink cung cấp một đường dẫn tốc độ cao giữa chúng, cho phép chúng giao tiếp với tốc độ dữ liệu cao nhất là 300 gigabyte mỗi giây(GB/s), tốc độ nhanh hơn 10 lần so với PCIe. Không giống như PCIe, với NVLink, một thiết bị có nhiều đường dẫn để lựa chọn và thay vì chia sẻ một hub trung tâm để giao tiếp, thay vào đó chúng sử dụng một mạng lưới cho phép trao đổi dữ liệu băng thông cao nhất giữa các GPU. Điều này giúp tăng tốc đáng kể các ứng dụng và mang lại hiệu suất tính toán thô lớn hơn so với GPU sử dụng PCIe. Bằng cách tăng tổng băng thông giữa GPU và các phần khác của hệ thống, luồng dữ liệu và tổng thông lượng hệ thống được cải thiện để nâng cao hiệu suất của khối lượng công việc. Trong trung tâm dữ liệu đám mây, GPU được coi như một thiết bị ngoại vi được sử dụng bởi các lõi CPU.

Hiểu khối lượng công việc của bạn để nắm bắt nhu cầu xử lý của bạn
Khối lượng công việc dành cho doanh nghiệp AI và học sâu là các hoạt động đa dạng và có nhiều khía cạnh. Việc chọn xây dựng một pipeline xử lý của bạn với GPU và / hoặc CPU đòi hỏi bạn phải hiểu khối lượng công việc và môi trường máy tính dự kiến của mình: thành công được xác định bằng cách kết hợp bộ xử lý phù hợp với ứng dụng của bạn. Như trong tất cả các quyết định kinh doanh, việc lựa chọn công cụ phù hợp cho công việc là rất quan trọng để đạt được mục tiêu hiệu suất mà bạn kỳ vọng.