
Nhân lực ngành khoa học dữ liệu – data analysis, big data – hiện đang có nhu cầu rất cao, chiếm vị trí số 1 trong danh sách Các công việc tốt nhất của Glassdoor ở Mỹ trong năm 2016 và 2017, với 4.840 vị trí và ở mức lương trung bình là 110.000 USD. Kỹ sư DevOps đứng thứ hai với mức lương trung bình là 110.000 USD, có 2.725 vị trí. Kỹ sư cơ sở dữ liệu vào hàng thứ 3, với 2.599 việc làm và mức lương trung bình là 106.000 USD. Khoa học dữ liệu là một trong những lĩnh vực khó tìm nhân lực nhất, mất năm ngày để tìm các ứng cử viên đủ điều kiện hơn mức trung bình của thị trường. Các nhà tuyển dụng sẵn sàng trả lương cao cho các chuyên gia có chuyên môn trong các lĩnh vực này. Hầu hết các công việc trong ngành khoa học dữ liệu đòi hỏi trình độ chuyên môn cao, điều này tiếp tục thúc đẩy nhu cầu và mức lương đối với các chuyên gia đáp ứng đủ năng lực trong lĩnh này.
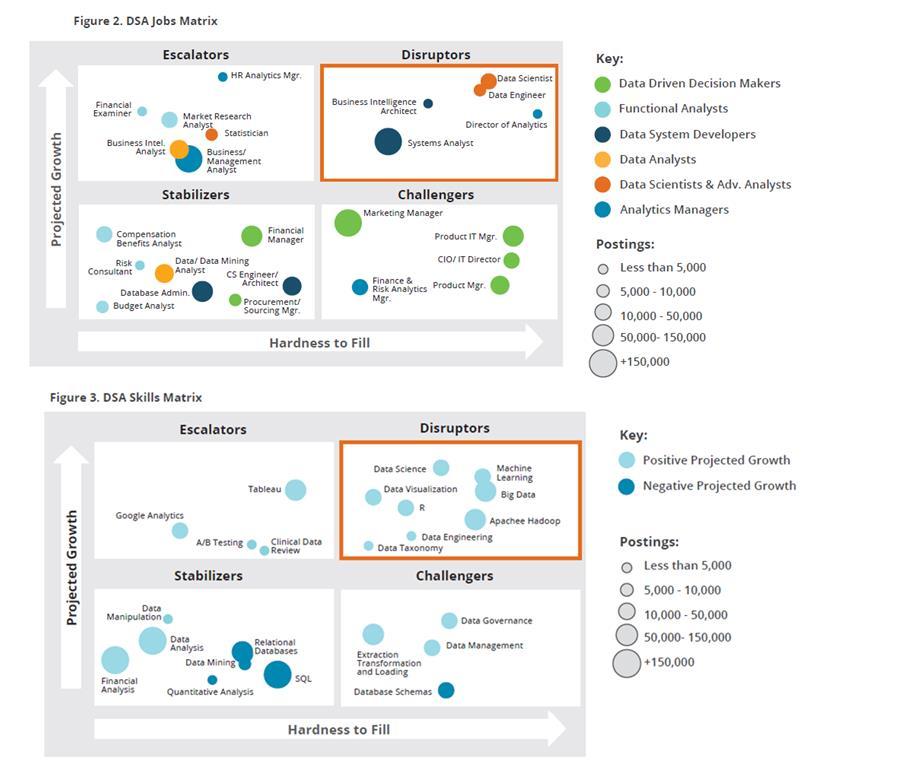
Theo Jim Webber, nhà khoa học trưởng tại Neo4j, sau đây là một danh sách ngắn các kỹ năng công nghệ thiết yếu nhất cho các nhà khoa học dữ liệu trong năm nay:

- Spark: Spark đang biến đổi cách các nhà khoa học dữ liệu hoạt động bằng cách cho phép phân tích dữ liệu có tính tương tác và lặp lại trên quy mô lớn. Các nhà khoa học dữ liệu đã quen thuộc với Spark sẽ có sức hút hơn với các công ty trong năm 2018, vì công cụ này giúp giảm chi phí, tăng lợi nhuận, cải thiện sản phẩm, giữ chân khách hàng và nhận ra các cơ hội mới.
- Apache Mahout: Nhu cầu công việc về phân tích và khoa học về dữ liệu là nổi bật nhất trong ngành dịch vụ tài chính, chiếm 19% trong tất cả các vị trí. Điều này phần lớn là do lo ngại ngày càng tăng về bảo mật trên Phố Wall, khiến các công ty thuê các nhà khoa học dữ liệu giải quyết các vấn đề như vi phạm an ninh mạng và trộm cắp danh tính. Các nhà khoa học dữ liệu có thể làm việc với các mô hình và framework trong lĩnh vực học máy – machine learning, chẳng hạn như Mahout, sẽ có nhu cầu cao.
- Cơ sở dữ liệu Graph – một dạng dữ liệu theo cấu trúc gồm các Node và Edge: Graph là phân nhóm phát triển nhanh nhất trong các hệ thống quản lý cơ sở dữ liệu và các đại gia công nghệ như AWS, Oracle và IBM đều có các dịch vụ Graph riêng của mình. Gartner dự đoán rằng 70% các công ty hàng đầu sẽ thí điểm một dự án cơ sở dữ liệu Graph có ý nghĩa vào năm 2018. Với việc sử dụng cơ sở dữ liệu Graph này, tính quen thuộc với công nghệ sẽ là chìa khóa. Các nhà khoa học dữ liệu có kiến thức để triển khai và quản lý cơ sở dữ liệu Graph, để tìm các kết nối trong dữ liệu của họ, sẽ thu hút nhất cho các vị trí hàng đầu trong ngành.
- Tableau: Dữ liệu doanh nghiệp đang tăng theo cấp số nhân. Số dữ liệu tuyệt vời này sẽ càng có ý nghĩa quan trọng, chừng nào bạn có thể hiểu hết được nó. Mặc dù Tableau không phải là một cái tên mới đối với các nhà khoa học dữ liệu, nó gần như là một kỹ năng mang tính đặt cược tại thời điểm này. Với những người ra quyết định kinh doanh dựa nhiều vào thấu hiểu dữ liệu, 2018 sẽ là năm có nhu cầu rất lớn với các nhà khoa học dữ liệu để mô hình hóa và thể hiện các thông tin phân tích được đến đúng người, vào đúng thời điểm.
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI
- NVIDIA GB200 NVL72: Tối đa hóa đào tạo và suy luận LLM với hàng nghìn tỷ tham số