
Bạn có thể đã nhiều lần nghe đến những tranh luận về vấn đề này: Cloud (nền tảng đám mây) hay On-premises (hạ tầng tại chỗ)? Hoặc cả hai? Có thể bạn muốn chuyển một số ứng dụng của mình lên đám mây. Nhưng ngoài ra, do những thay đổi về chính sách bảo mật dữ liệu gần đây, bạn có thể phải di chuyển một số dữ liệu khách hàng quay trở lại với on-premises. Cuối cùng, có thể nhu cầu của bạn quá lớn nên sẽ là hợp lý khi đầu tư hạ tầng tại chỗ cho nhu cầu cơ bản của bạn, nhưng tận dụng đám mây khi nhu cầu gia tăng đột biến (ở đây tức là mô hình đám mây lai – hybrid cloud).
Chỉ vì bạn đã đưa ra một lựa chọn cho hạ tầng của mình không có nghĩa là câu trả lời tương tự sẽ áp dụng cho cách tiếp cận với Deep Learning của bạn. Đào tạo mạng nơron sâu bao gồm các yêu cầu đặc thù làm thay đổi cơ bản về những thảo luận kiểu này. Bao gồm:
- Bộ tăng tốc phần cứng chuyên dụng, thường là GPU
- Lưu trữ cho các tập dữ liệu đào tạo lớn liên tục phát triển
- I/O hiệu suất cao giữa phần cứng chuyên dụng này và dung lượng lưu trữ lớn
Mặc dù xu hướng nổi lên trong CNTT là di chuyển sang đám mây, chúng tôi cho rằng những yêu cầu này có thể làm cho việc đầu tư cơ sở hạ tầng tại chỗ cho Deep Learning trên quy mô lớn, đặc biệt khi cần năng lực xử lý GPU cơ bản luôn ở mức cao, trở nên cần thiết.

Khi bạn lần đầu tiên bắt đầu với Deep Learning, sử dụng một dịch vụ đám mây sẽ có ý nghĩa. Với khoản đầu tư trả trước tối thiểu, cả về chi phí và thời gian, bạn có thể thực hiện đào tạo mô hình đầu tiên của mình bằng GPU. Tuy nhiên, khi “nhóm” một người của bạn phát triển lên năm người và thử nghiệm đơn lẻ của bạn trở thành hàng trăm hoặc thậm chí hàng nghìn, thì chi phí tiết kiệm khi tiến hành tại chỗ có thể đạt gần 10 lần so với các đám mây công cộng lớn. Thêm vào đó là sự linh hoạt tăng lên trong những gì bạn có thể xây dựng và bảo mật dữ liệu tốt hơn, và đột nhiên on-premises bắt đầu trông ngày càng hấp dẫn cho những tham vọng Deep Learning đang phát triển của bạn.
Và bây giờ, chúng ta hãy đi sâu vào chi tiết hơn một chút để giải thích lý do của chúng. Như có thể thấy, bạn có bốn lựa chọn.
Cloud
- Nhà cung cấp đám mây truyền thống : Các nhà cung cấp đám mây lớn như Amazon Web Services (AWS), Google Cloud Platform (GCP) và Microsoft Azure.
- Nhà cung cấp đám mây cụ thể cho Machine Learning : Các công ty như Paperspace điều chỉnh các dịch vụ của họ để hỗ trợ tốt hơn quy trình Deep Learning (ví dụ: bằng cách tập trung vào các phiên bản GPU và các khả năng phần mềm bổ sung).
On-Premises
- server/deep-learning/">Máy chủ Deep Learning được xây dựng sẵn: Nvidia bán các máy trạm Deep Learning, như hệ thống DGX của hãng . Các công ty khác, như Lambda Labs , AMAX và Boxx , xây dựng các máy trạm tùy chỉnh dựa trên nhu cầu của bạn.
- Máy trạm Deep Learning được xây dựng từ đầu: Có rất nhiều tài nguyên với hướng dẫn từng bước về những thành phần cần mua và cách thiết lập.
Tiếp theo, chúng tôi sẽ so sánh cách các tùy chọn này hoạt động trên năm tiêu chí quan trọng nhất của chúng tôi. Phân tích của chúng tôi được tóm tắt trong bảng dưới đây.

Hiệu suất
GPU đã trở thành tiêu chuẩn để đào tạo các mô hình Deep Learning nhờ băng thông bộ nhớ cao và khả năng thực hiện nhiều phép tính song song. Hiệu suất của cơ sở hạ tầng Deep Learning của bạn liên quan trực tiếp đến chất lượng của GPU mà nó sử dụng.
Với các bản phát hành phần cứng mới và các thay đổi đối với dịch vụ của các nhà cung cấp dịch vụ đám mây, các câu trả lời ở đây có thể nhanh chóng trở nên lỗi thời. Ví dụ, nếu chúng tôi đã viết bài đăng này một vài năm trước, tại chỗ sẽ là người chiến thắng rõ ràng trong hạng mục này. AWS cung cấp quyền truy cập vào các phiên bản p2 của nó, được xây dựng dựa trên thẻ Nvidia K80 (ra mắt năm 2014). Tuy nhiên, nếu bạn đã xây dựng máy trạm của riêng mình, bạn có thể đã sử dụng các thẻ mới hơn, như Nvidia Titan X (tháng 8 năm 2016) hoặc GTX 1080 Ti (tháng 3 năm 2017), mang lại hiệu suất cao hơn.
Các nhà cung cấp đám mây kể từ đó đã nâng cấp đáng kể các dịch vụ GPU của họ. Loại phiên bản p3 của AWS, thế hệ phiên bản GPU đa năng mới nhất của họ, ra mắt vào tháng 10 năm 2017 và cung cấp GPU V100 của Nvidia, có thể mang lại hiệu suất cao nhất trên 100 TFLOPS cho đào tạo và suy luận. Azure và GCP ngay sau đó đã làm theo, lần lượt đưa V100 vào tháng 3 và tháng 4 năm 2018 . Gần đây hơn, vào tháng 5 năm 2020, Nvidia đã phát hành máy gia tốc A100 dựa trên Ampere, đã có sẵn trong chương trình alpha của GCP, với kế hoạch sẽ có sẵn vào cuối năm 2020.
Người dùng tại chỗ có quyền tự do lựa chọn GPU để sử dụng. Mặc dù bạn có thể mua cho mình một Nvidia DGX Station với 8 GPU A100, bạn cũng có thể chọn xây dựng một hệ thống với các thẻ từ dòng tiêu dùng của công ty. Rất may, có rất nhiều tài nguyên ngoài kia đánh giá hiệu suất tương đối của các mô hình này trên khối lượng công việc Deep Learning để giúp đưa ra quyết định của bạn. Cuối cùng, bởi vì giờ đây bạn có thể truy cập cùng một mẫu GPU hàng đầu cả trên đám mây và tại chỗ, chúng tôi cho rằng danh mục này là sự ràng buộc giữa hai tùy chọn.
Ngoài GPU, I/O hiệu suất cao cũng rất quan trọng để tăng thời gian đào tạo mô hình. Nếu không có khả năng truyền dữ liệu đủ nhanh từ bộ nhớ từ xa hoặc thậm chí cục bộ, các GPU mạnh mẽ khổng lồ của bạn sẽ không hoạt động. Một lần nữa, không có nhiều sự chênh lệch về hiệu suất giữa các giải pháp đám mây và tại chỗ ở đây, vì cả hai đều giúp bạn có thể sử dụng các loại lưu trữ cục bộ và từ xa nhanh nhất, cụ thể là SSD dựa trên NVMe. Tuy nhiên, chúng tôi đề cập đến điều này để nhấn mạnh rằng việc thiết kế đúng hệ thống con lưu trữ của bạn để bắt kịp với GPU của bạn là điều cần thiết để đạt được hiệu suất tối ưu.
Chi phí
Chúng tôi đã thực hiện phân tích chi phí của riêng mình kể từ tháng 7 năm 2020 với các mẫu từ từng cái trong số bốn loại. Đối với các tùy chọn đám mây, chúng tôi đã xem xét AWS và GCP khi xem xét “các nhà cung cấp đám mây truyền thống” và chọn Paperspace làm nhà cung cấp đám mây “đặc thù cho ML” của chúng tôi.
Chúng tôi đã khảo sát ba mức hiệu suất – thấp, trung bình và cao – dựa trên mô hình GPU. Chúng tôi cũng xem xét hai giả định về hiệu suất sử dụng: thấp (10%) và cao (100%).
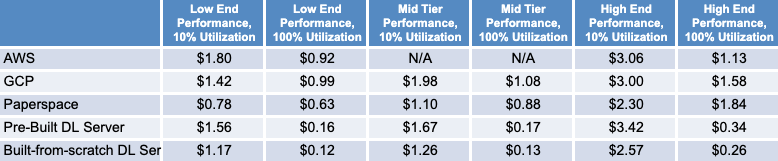
Việc sử dụng ảnh hưởng đến lựa chọn giá nào là kinh tế nhất từ các nhà cung cấp dịch vụ đám mây. Giả sử mức sử dụng cao, bạn sẽ muốn sử dụng các phiên bản dành riêng, nơi bạn trả tiền cho việc sử dụng liên tục trong một khoảng thời gian cố định để đổi lấy mức giá chiết khấu theo giờ. Phân tích của chúng tôi là lạc quan, với các kịch bản sử dụng cao báo cáo giá với giả định mức sử dụng cam kết 3 năm (cung cấp chiết khấu cao hơn so với hợp đồng 1 năm). Nếu hiệu suất sử dụng của bạn không đủ cao, thì giá theo yêu cầu là lựa chọn tốt hơn vì bạn chỉ trả tiền cho trường hợp nó đang chạy. Điều này cũng đúng đối với các nhà cung cấp đám mây ML, những người cung cấp các mô hình định giá tương tự. Lưu ý rằng với những thứ này, bạn cũng phải trả thêm phí hàng tháng cho bộ công cụ của họ (với các tính năng như trực quan hóa dữ liệu và sổ ghi chép Jupyter 1 lần nhấp).
Khi xem xét chi phí tại chỗ, chúng tôi không chỉ bao gồm chi phí trả trước của việc mua và lắp ráp phần cứng mà còn cả chi phí điện năng, làm mát, mạng và bảo trì. Để hào phóng với các dịch vụ đám mây, chúng tôi ước tính các chi phí này bằng 50% chi phí phần cứng mỗi năm (khấu hao trong 3 năm) cho phân tích của chúng tôi.
Dựa trên phân tích của chúng tôi, các giải pháp tại chỗ là người chiến thắng rõ ràng về giá cả trong các trường hợp sử dụng cao, với các phương pháp tiếp cận từ đầu được xây dựng từ đầu đến cao cấp và trung cấp có giá thấp hơn 4,3 lần và 6,5 lần so với tùy chọn đám mây rẻ nhất, tương ứng.
Ngay cả trong các trường hợp sử dụng thấp, tại chỗ vẫn rẻ hơn các dịch vụ đám mây công cộng truyền thống ở cấp hiệu suất trung bình và cao. Mặc dù Paperspace dường như là người chiến thắng về giá cho các trường hợp sử dụng thấp, lợi thế này chỉ tồn tại trong thời gian ngắn. Bằng cách tăng hiệu suất sử dụng lên 11% ở phân khúc cao cấp và 15% ở phân khúc trung cấp, phương pháp xây dựng từ đầu đã trở lại ngang giá.
Chúng tôi cho rằng kịch bản sử dụng cao là điều quan trọng nhất cần tập trung vào. Với sự phát triển về bộ dữ liệu và độ phức tạp của mô hình, một mô hình duy nhất có thể mất nhiều ngày để đào tạo. Thêm vào đó là vô số siêu tham số mà bạn sẽ muốn quét để đạt được hiệu suất tối ưu và bạn nên có nhiều thử nghiệm để giữ cho phần cứng của mình luôn bận rộn.
Thiết lập
Chúng tôi coi thiết lập là khối lượng công việc cần thiết trước khi bạn có thể bắt đầu đào tạo mô hình Deep Learning đầu tiên của mình trên một GPU. Trong danh mục này, các nhà cung cấp đám mây dành riêng cho ML cung cấp giải pháp thân thiện với người mới bắt đầu nhất. Các phiên bản đám mây của họ được định cấu hình đầy đủ cho Deep Learning, với CUDA, cuDNN, TensorFlow và các khuôn khổ Deep Learning phổ biến khác được cài đặt sẵn. Chúng giúp bạn dễ dàng khởi chạy sổ ghi chép Jupyter cũng như truy cập các tập dữ liệu công khai và các dự án mẫu. Tuy nhiên, các nhà cung cấp đám mây truyền thống đã bắt đầu bắt kịp. Ví dụ: với AWS Deep Learning AMI, bạn có được một môi trường được định cấu hình đầy đủ để chạy các thử nghiệm Deep Learning. Phần khó khăn nhất khi bắt đầu với giải pháp đám mây có thể là tải lên tập dữ liệu của bạn, đây có thể là một quá trình chậm và có khả năng tốn kém (nếu có chi phí chuyển dữ liệu ra khỏi nguồn gốc).
Các giải pháp tại chỗ có thể yêu cầu nhiều công việc trước hơn, tùy thuộc vào tùy chọn bạn chọn. Ví dụ: tại AI được xác định gần đây, chúng tôi đã mua một máy trạm Deep Learning được xây dựng sẵn mà hầu như không yêu cầu thiết lập. Nó được cài đặt sẵn Ubuntu, tất cả các trình điều khiển GPU cần thiết và các khung DL yêu thích của chúng tôi. Sau khi cắm nó vào nguồn điện và ethernet, chúng tôi đã sẵn sàng để bắt đầu! Với tùy chọn xây dựng từ đầu, nỗ lực thiết lập chủ yếu tập trung vào việc lắp ráp máy trạm. Đây có thể là một lựa chọn tốn thời gian và có khả năng tốn kém (nếu bạn làm hỏng bất kỳ bộ phận nào trên đường đi). Tuy nhiên, thiết lập về mặt phần mềm dễ dàng hơn bạn nghĩ. Mặc dù bạn vẫn có thể phải cài đặt một số trình điều khiển, nhưng nhờ sự gia tăng của quá trình container hóa, bạn có thể dễ dàng nhận được hình ảnh cho khung Deep Learning mà mình lựa chọn.
Sau khi giải pháp cơ sở hạ tầng của bạn được thiết lập để xử lý khối lượng công việc đào tạo Deep Learning cơ bản, sau đó sẽ dễ dàng sử dụng Quyết tâm chuyển đổi thiết lập của bạn thành một nền tảng mạnh mẽ mà toàn bộ nhóm của bạn có thể sử dụng để hợp lý hóa khối lượng công việc Deep Learning nâng cao hơn.
Bảo trì
Các nhà cung cấp truyền thống đi trước trong danh mục này, họ đã xây dựng công việc kinh doanh của mình xung quanh việc cung cấp thời gian hoạt động liên tục. Các nhà cung cấp ML cụ thể cũng quảng cáo SLA (Paperspace, chẳng hạn, hứa hẹn 99,99% thời gian hoạt động với dịch vụ cấp doanh nghiệp của họ ).
Mặt khác, khi hệ thống tại chỗ của bạn chắc chắn có vấn đề gì xảy ra, bạn sẽ phải giải quyết. Có một danh sách các lỗi có thể xảy ra với máy giặt – khởi động lại đột xuất, mất nguồn, sự cố mạng và chạy quá tải bộ nhớ của bạn, chỉ để kể tên một số. Tuy nhiên, một phần đau đầu này có thể được bù đắp bằng cách mua một máy chủ DL được xây dựng sẵn bao gồm hỗ trợ. Hoặc, với một khoản đầu tư tại chỗ đủ lớn, bạn có thể thuê một chuyên gia CNTT chuyên dụng, ngay cả khi bán thời gian.
Bảo vệ
Trong khi các nhà cung cấp đám mây tiếp tục đầu tư đáng kể vào bảo mật, các giải pháp tại chỗ tiếp tục là tiêu chuẩn vàng. Lợi thế rõ ràng của tại chỗ là dữ liệu và mô hình đào tạo không bao giờ rời khỏi cụm. Trong khi một số lĩnh vực trước đây đặc biệt nhạy cảm với quyền riêng tư dữ liệu (tài chính, chính phủ, chăm sóc sức khỏe), việc châu Âu thông qua Quy định chung về bảo vệ dữ liệu (GDPR) đã khiến nhiều công ty bắt đầu suy nghĩ nghiêm túc về vấn đề này. Nếu không làm như vậy có thể dẫn đến một sai lầm đắt giá. Tiền phạt do vi phạm luật có thể lên tới 4% tổng doanh thu toàn cầu, với Google và Facebook đã phải hứng chịu các vụ kiện 8,8 tỷ USD vào ngày GDPR có hiệu lực.
Làm thế nào để AI được xác định phù hợp?
Bất kể bạn hạ cánh ở đâu trong đám mây so với cuộc tranh luận tại chỗ, nền tảng mã nguồn mở của Xác định phù hợp với chiến lược cơ sở hạ tầng của bạn. Về phía đám mây, chúng tôi nhấn mạnh vào khả năng chịu lỗi, khả năng tái tạo, tính năng tự động cân bằng GPU và hỗ trợ phiên bản ưu tiên cung cấp cho bạn sự linh hoạt để bùng nổ khối lượng công việc đào tạo Deep Learning trên đám mây một cách có ý thức về chi phí. Về mặt tại chỗ, Xác định giảm thiểu chi phí thiết lập và bảo trì bằng cách cung cấp các vùng chứa Docker dành riêng cho Deep Learning để chạy thử nghiệm và cho phép các thành viên trong nhóm chia sẻ liền mạch các GPU được tìm kiếm nhiều.
Bất kể cuối cùng bạn đưa ra lựa chọn cơ sở hạ tầng nào, các nhà phát triển mô hình của bạn sẽ có thể tận dụng khả năng thử nghiệm Deep Learning của Xác định: đào tạo phân tán, tìm kiếm meta parameter song song dựa trên các phương pháp dừng sớm hiện đại nhất, theo dõi thử nghiệm và đẩy – khả năng tái tạo nút.
- Kiểm tra các ví dụ ở đây và ở đây.
- Kể từ tháng 12 năm 2017, Nvidia đã cập nhật thỏa thuận cấp phép người dùng cuối cho các trình điều khiển GPU cấp dành cho người tiêu dùng (Titan và GeForce), hạn chế việc sử dụng phần mềm trong các trung tâm dữ liệu . Không rõ chính xác điều gì tạo nên một “trung tâm dữ liệu”, cũng như liệu Nvidia có thực sự thực thi điều này hay không (họ sẽ làm việc với khách hàng trên “ cơ sở từng trường hợp ”).
- Phân tích này cho thấy hiệu suất khác nhau đối với cùng một GPU V100 trên Paperspace và Amazon EC2 do các hạn chế I/O.
- Các mô hình GPU khác nhau giữa các tùy chọn cho từng cấp hiệu suất bởi vì chúng tôi bị hạn chế bởi những gì nhà cung cấp đám mây cung cấp. Trong trường hợp các mô hình GPU không khớp, chúng tôi đã chọn một mô hình gần tương đương (bằng cách xem xét hiệu suất cao nhất, bộ nhớ và băng thông bộ nhớ). Xem Bảng 3 để biết thêm chi tiết. Lưu ý rằng AWS không cung cấp GPU trung cấp. Trong trường hợp K80, giá đã được điều chỉnh để giải thích cho thực tế là AWS và GCP báo giá trong GPU, không phải bởi bo mạch (bo mạch K80 chứa 2 GPU mỗi loại).

Bảng 3: Mô hình GPU trong từng loại - Tất cả ba nhà cung cấp đám mây công cộng cũng cung cấp giá giao ngay, cho phép bạn đặt giá thầu cho dung lượng chưa sử dụng. Mặc dù đây có vẻ là một cách tuyệt vời để tiết kiệm tiền, nhưng nó phải trả giá bằng độ tin cậy. Phân tích này cho thấy rằng các phiên bản điểm GPU đều có nhiều khả năng được sử dụng trước và ít có khả năng hơn các loại phiên bản chung. Mặc dù các giải pháp thay thế tồn tại và một số doanh nghiệp tận dụng lợi thế của tầng này, nhưng nó đòi hỏi nỗ lực kỹ thuật đáng kể. Vì lý do này, chúng tôi sẽ không tập trung vào định giá giao ngay trong phân tích của mình.
- Xem https://www.amax.com/wp-content/uploads/2018/03/AMAX-CloudvOnPrem-White-Paper.pdf.
- Giá cho máy chủ DL được tạo sẵn được tính từ việc lấy giá cơ sở của máy chủ được xây dựng từ đầu và cộng thêm 50%. Ước tính này đến từ việc xem xét sự khác biệt về giá giữa máy chủ được xây dựng sẵn AI được xác định đã mua và định giá từng thành phần giống nhau (mặc dù chúng ta nên lưu ý rằng máy chủ được tạo sẵn cũng bao gồm hỗ trợ khách hàng).
Nguồn Determined AI
Bài viết liên quan
- Máy chủ Supermicro X14: Hiệu suất mạnh mẽ, hiệu quả tối đa cho AI, Cloud, Storage, 5G/Edge
- Tôi có cần CPU kép không?
- NVIDIA HGX AI Supercomputer: Nền tảng điện toán AI hàng đầu thế giới
- NVIDIA SuperPOD DGX GB200: Kỷ nguyên của AI nghìn tỷ tham số
- Nền tảng NVIDIA Blackwell: Tạo nên kỷ nguyên điện toán mới
- NVIDIA DGX B200: Nền tảng AI thống nhất cho Training, Fine-tuning và Inference AI